|
|
||
|
|
||
|
|
Chapitre 4Etude expérimentale4.1 IntroductionDans le chapitre précédent, nous avons introduit un nouvel algorithme, appelé PRINCE, pour l'extraction des itemsets fermés fréquents, leurs générateurs minimaux associés ainsi que les regles génériques informatives valides. A cet effet, PRINCE se distingue par la construction de la relation d'ordre partiel contrairement aux algorithmes existants. Cette relation d'ordre partiel est maintenue entre les générateurs minimaux fréquents sous forme d'une structure partiellement ordonnée appelée treillis des générateurs minimaux. A partir de cette structure, l'extraction des regles génériques informatives valides devient immédiate. Dans ce chapitre, nous présentons quelques optimisations apportées a notre algorithme et nous mesurons leurs impacts sur les performances de l'algorithme PRINCE 1. Ensuite, nous présentons une évaluation expérimentale - menée sur des bases benchmark et des bases "pire des cas" - permettant d'analyser les caractéristiques de l'algorithme PRINCE et de comparer ses performances a celles des algorithmes CLOSE, A-CLOSE et TITANIC. Ces derniers se limitent a extraire les itemsets fermés fréquents et leurs générateurs minimaux seulement. Leurs codes sources ont été mis a notre disposition par Yves Bastide. 4.2 Environnement d'experimentation4.2.1 Environnement materiel et logiciel Toutes les experimentations ont ete realisees sur un P C muni d'un processeur Pentium IV ayant une frequence d'horloge de 2,4 GHz et 512 Mo de memoire RAM (avec 2 Go d'espace d'echange ou Swap) tournant sous la plate-forme SuSE Linux 9.0. PRINCE est implante en Langage C tandis que CLOSE, A-CLOSE et TITANIC le sont en C-h-h. Les programmes ont ete compiles avec le compilateur gcc 3.3.1. 4.2.2 Description des executables Dans le cadre de nos experimentations, nous avons utilise les executables decrits par le tableau 4.1.
TAB . 4.1: Description des executables des differents algorithmes 4.2.3 Bases de test Dans le cadre de nos experimentations, nous avons comptabilise le temps d'execution total des algorithmes sur des bases benchmark ainsi que sur des bases "pire des cas". Tout au long de ce chapitre, les figures presentees ont une echelle logarithmique. 4.2.3.1 Bases benchmark Les bases benchmark sont divisees en des bases denses et des bases eparses (2). Les caracteristiques de ces bases sont resumees par le tableau 4.3. Ce tableau definit, pour chaque base, son type, le nombre de transactions, le nombre d'items et la taille moyenne des 2L'ensemble de ces bases est disponible a l'adresse suivante : http :// fimi.cs.helsinki.fi/data. transactions. La base PUMSB contient des données de recensement (cad des données statistiques). La base MUSHROOM contient les caractéristiques de diverses espèces de champignons. Les bases CONNECT et CHESS sont dérivées a partir des étapes de jeux respectifs qu'elles représentent. Ces bases sont fournies par U C Irvine Machine Learning Database Repository (3). Typiquement, ces bases sont très denses (cad elles produisent plusieurs itemsets fréquents longs même pour des valeurs de supports élevées). T10I4D100K et T40I10D100K sont deux bases synthétiques générées par un programme développé dans le cadre du projet dbQUEST (4). Ces bases simulent le comportement d'achats des clients dans des grandes surfaces [36]. Le tableau 4.2 présente les différents paramètres des bases synthétiques. La base RETAIL [17] est fournie par une grande surface anonyme située en Belgique. La base ACCIDENTS [28] est obtenue de l'institut national belge de statistiques et représente des statistiques sur les accidents du trafic survenus dans la région de Flandre (Belgique) entre 1 991 et 2 000.
TAB . 4.2 -- Paramètres des bases synthétiques
TAB . 4.3 -- Caractéristiques des bases benchmark 3http ://www.ics.uci.edu/~mlearn/ML Repository.html . 4 Le generateur des bases synthetiques est disponible a l'adresse suivante http :// www.almaden.ibm.com/software/quest/ Resources/datasets/data/ . 4.2.3.2 Bases "pire des cas" Dans le cadre de nos experimentations, nous avons realise des tests sur des bases "pire des cas". La configuration de chacune de ces bases est une legère modification de celle presentee par Fu et Nguifo dans [26]. La definition d'une base "pire des cas" est comme suit : Definition 9 Une base "pire des cas" est une base oit la taille de l'ensemble des items I est égale a n et celle de l'ensemble des transactions O est égale a (n+1). Dans cette base, cha que item est vérifié par n transactions différentes. Cha que transaction, parmi les n premières, est vérifiée par (n-1) items différents. La dernière transaction est vérifiée par tous les items. Les transactions sont toutes différentes deux a deux. Les items sont tous différents deux a deux.
FIG . 4.1 -- Exemple d'une base "pire des cas" avec n4 La Figure 4.1 presente un exemple d'une base "pire des cas" avec n egal a 4. Une base "pire des cas" donne, pour une valeur de minsup egale a 1, un treillis complet des itemsets frequents contenant 2' itemsets frequents. Dans le pire des cas, le treillis des itemsets frequents se confond avec le treillis des itemsets fermes frequents ainsi qu'avec le treillis des générateurs minimaux. L'algorithme BASE-PIRE-CAS, dont le pseudo-code est donne par l'algorithme 5, permet de generer une base "pire des cas" dans un fichier F et pour une valeur n donnee. 4.3 Optimisations et evaluations1 Algorithme : BASE-PIRE-CAS Donnees : - Un entier n. Resultats : - Un fichier F contenant une base "pire des cas" de dimension (n + 1)×n. 2 debut 3 4 5 6 7 8 pour (i--1; i < n; i++) faire pour (j--1 ; j < n; j++) faire si i =~ j alors
écrire(F,i); pour (i--1; i < n; i++) faire
écrire(F,i); 9 fin Algorithme 5 : BASE-PIRE-CAS nombre de comparaisons. Dans toutes les figures qui vont suivre, nous utilisons une valeur de minconf égale a 0 (cad toute regle générique extraite est valide). 1. Representation compacte de la base : lors de la premiere étape et afin de réduire le cofit du calcul des supports des candidats générateurs minimaux (cf. la procédure GEN-GMS page 43), nous utilisons des techniques permettant de réduire la taille de la base a traiter. Pour cela, nous introduisons une structure de données appelée IT-BDT (Itemset-Trie-BaseDeTransaction). IT-BDT est une modification de la structure de données Itemset-Trie [8] permettant de stocker le contexte d'extraction en mémoire centrale et de retrouver les items relatifs aux différentes transactions. L'utilisation d'une structure interne pour stocker le contexte d'extraction est adoptée par plusieurs travaux, tels que [12, 37, 62]. Dans la structure Itemset-Trie, le compteur que contient un nceud N indique le nombre d'occurrences des transactions ayant en commun N. Dans la figure 4.2 (Gauche), le nceud contenant l'itemset A possede un compteur égal a 3 car c'est l'intersection de trois transactions, a savoir A CD, AB CE et AB CE. Dans la structure IT-DBT, ce compteur prend pour valeur 0 si les items se trouvant sur le chemin menant de la racine a N ne représentent pas une transaction sinon le compteur prend pour valeur le nombre de fois que la transaction s'est répétée dans la base de transactions. Dans la figure 4.2 (Droite), le nceud contenant l'itemset A a un compteur égal a 0 car A ne forme pas a lui seul une
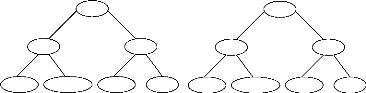
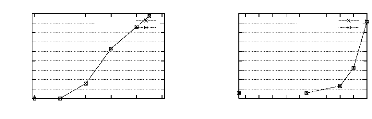
(CD,1) (BCE,2) (A,3) root (CE,1) (E,1) (B,2) (CD,1) (BCE,2) (A,0) root (CE,1) (E,1) (B,0) FIG . 4.2 -- La structure Itemset-Trie (Gauche) et la structure IT-BDT (Droite) associees au contexte d'extraction de la Figure 3.1 transaction. De plus, le calcul du support des 1-itemsets se fait en même temps que la construction de la structure IT-BDT. Notons que la structure IT-BDT permet aussi de mettre en place un processus de fouille interactif etant donne qu'il n'y a nul besoin de la reconstruire si nous changeons la valeur de minsup, contrairement A d'autres structures telles que FP-Tree [34, 35] et Patricia-Trie [53], etc. Afin de ne pas faire perdre a la structure IT-DBT ce dernier avantage, nous n'eliminons, de cette structure, ni les items infrequents ni ceux ayant même support que celui de l'ensemble vide. Cependant, lors du parcours de cette structure, seuls les items frequents de supports inferieurs a celui de l'ensemble vide (cad les items generateurs minimaux frequents) seront pris en compte. De plus, toute transaction ne depassant pas la taille des candidats n'est pas prise en compte etant donne qu'elle ne contient aucun candidat. Evaluation experimentale de cette optimisation : Nous allons tester une version de PRINCE oft nous utilisons une representation compacte de la base comparee a une version oft la base a traiter se trouve sur le disque et aucun traitement relatif aux transactions n'est effectue. Pour realiser ce test, nous avons choisi les bases PUMSB, CONNECT et ACCIDENTS etant donne que, pour ces bases, le calcul du support des candidats est une operation coliteuse vu le nombre ainsi que la taille moyenne des transactions que contiennent ces bases. Pour les trois bases sus-mentionnees, la figure 4.3 montre les temps d'execution de PRINCE dans les deux cas : avec utilisation de la representation compacte de la base (cf. courbe "avec RC") et sans utilisation de la representation compacte de la base (cf. courbe "sans RC").
Temps d'execution (en seconde) 1024 256 512 128 64 32 16 8 90 80 Connect 70 60 50 Temps d'execution (en seconde) 4096 2048 1024 256 512 128 64 32 16 8 90 80 70 Accidents 60 avec Rc 50 40 30 Temps d'execution (en seconde) 4096 2048 1024 256 512 128 64 32 16 4 2 8 95 90 Pumsb 85 avec Rc 80 75 avec Rc Minsup (en %) Minsup (en %) Minsup (en %) FIG . 4.3 -- Effet de l'utilisation d'une représentation compacte de la base sur les performances de PRINCE tées (une réduction comprise entre 20,87% a 75,00% pour PUMSB, entre 10,84% et 61,90% pour CONNECT et entre 14,67% et 80,76% pour ACCIDENTS). Cette réduction diminue proportionnellement a la baisse des valeurs de minsup. Ceci peut être expliqué par le fait que plus la valeur de minsup baisse, moins il y a d'items infréquents. D'oft, seule l'utilisation d'IT-BDT reste bénéfique pour les performances de PRINCE. 2. Reduction du nombre de comparaisons : Afin de réduire le nombre de comparaisons effectuées lors de la deuxieme étape (cf. la procédure GEN-ORDRE page 50), nous avons utilisé les optimisations suivantes : (a) La premiere optimisation consiste a mettre en place un traitement permettant de savoir si chaque générateur minimal fréquent est aussi un fermé ou non. Ce même traitement est utilisé dans l'algorithme A-CLOSE (cf. page 26). Dans le cas de ce dernier, ce traitement indique a partir de quelle taille des générateurs minimaux fréquents, il y aurait un calcul des fermetures. Dans notre cas et a la fin de la premiere étape, ce traitement permet d'indiquer si l'algorithme PRINCE nécessite ou non d'exécuter la deuxieme étape. En effet, si chaque générateur minimal fréquent est aussi un fermé, le treillis des générateurs minimaux est construit des la premiere étape et l'algorithme PRINCE n'a pas a exécuter la procédure GEN-ORDRE. Un simple parcours de l'ensemble est alors suffisant. Il n'y alors pas de regle exacte informative. Etant donné que nous stockons dans le champ sous-ens-directs, des liens vers les sous-ensembles de taille (k-1) de tout générateur minimal g de taille k, nous avons les prémisses nécessaires pour extraire les regles approximatives informatives valides. version de PRINCE oft la procédure GEN-ORDRE est exécutée, bien que chaque générateur minimal fréquent est aussi un fermé, comparée a une version oft cette procédure n'est pas exécutée. Pour réaliser ce test, nous allons utiliser la base ACCIDENTS étant donné que pour des valeurs de minsup supérieures ou égales a 40%, chaque générateur minimal fréquent est un fermé. La figure 4.4 montre les temps d'exécution de PRINCE dans les deux cas : avec exécution de GEN-ORDRE (cf. courbe "avec G-O") et sans exécution de GEN-ORDRE (cf. courbe "sans G-O"). Temps d'execution (en seconde) 256 128 64 32 16 8
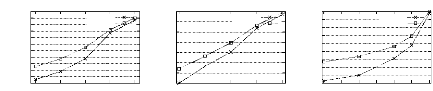
90 80 Accidents 70 avec G-O 60 50 40 Minsup (en %) FIG . 4.4 -- Effet de l'exécution de la procédure GEN-ORDRE sur les performances de PRINCE Le fait de ne pas exécuter la procédure GEN-ORDRE permet de réduire les temps d'exécution de PRINCE de 2,23% jusqu'a 16,66%. (b) La deuxième optimisation consiste a utiliser les 2-itemsets fréquents non générateurs minimaux pour déterminer la relation entre les items fréquents. Ces items ont tous un sous-ensemble commun a savoir l'ensemble vide. Soit Z un itemset fréquent non générateur minimal et soient x et y les items le composant. En comparant le support de Z a ceux de x et y, nous pouvons connaitre la relation entre Cx et Cy. Dans la premiere étape de l'algorithme PRINCE, nous ajoutons donc un traitement qui, des le calcul des supports des candidats générateurs minimaux de taille 2, traite chaque 2-itemset fréquent non générateur minimal pour déterminer la relation entre les classes d'équivalence des items le composant. Le traitement d'un 2-itemset générateur minimal Z, ne sert a rien puisque les classes d'équivalence des items le composant sont incomparables (sinon Z, ne serait pas générateur minimal). L'utilisation des candidats générateurs minimaux de taille 2 est favorisée par le fait que tous ces candidats vérifient l'idéal d'ordre et nous avons ainsi le support de toutes les combinaisons possibles, de taille 2, d'items fréquents. Evaluation expérimentale de cette optimisation : Afin de tester l'effet de l'utilisation des 2-itemsets fréquents non générateurs minimaux pour déterminer la relation entre les items fréquents, nous allons utiliser la base RETAIL. En effet, dans cette base, le nombre d'items est très élevé (16470 items). Ceci rend élevé le nombre de comparaisons entre les 1-itemsets fréquents pour de basses valeurs de minsup. La figure 4.5 montre les temps d'exécution de PRINCE dans les deux cas : prise en compte des 2-itemsets fréquents non générateurs minimaux (courbe "avec 2-freqs-Non-GMs") ou non (courbe "sans 2-freqs-Non-GMs"). Temps d'execution (en seconde) 4096 2048 1024 256 512 128 64 32 16
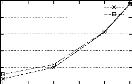
0.1 avec 2-freqs-Non-GMs 0.08 0.06 Retail 0.04 0.02 0 Minsup (en %) FIG . 4.5 -- Effet de l'utilisation des 2-itemsets fréquents non générateurs minimaux sur les performances de PRINCE L'utilisation des 2-itemsets fréquents non générateurs minimaux permet de réduire les temps d'exécution de PRINCE de 1,71% jusqu'a 13,79%. (c) La troisième optimisation consiste a stocker, pour chaque générateur minimal fréquent g, une liste prohibée notée lg, des générateurs minimaux fréquents auxquels nous avons comparé g a leurs listes de successeurs immédiats. Ceci permet d'éviter de comparer g a une liste des successeurs immédiats L plus qu'une fois étant donné que les comparaisons qui en découlent sont superflues. En effet, le résultat de ces comparaisons est le même que celui de la première comparaison de g avec L. La notion de liste prohibée est étendue au niveau de la classe d'équivalence. Ainsi, si g est comparé avec le représentant de sa classe d'équivalence R., nous ajoutons les éléments de lg a la liste prohibée de R. (cad lR) étant donné que le reste des comparaisons est poursuivi avec ce dernier. Evaluation expérimentale de cette optimisation : Pour tester l'effet de l'utilisation de la liste prohibée, nous utilisons la base MUSHROOM. En effet, pour cette base, la construction de l'ordre partiel est l'étape la plus coUteuse (le calcul du support est favorisé par un nombre réduit de transactions de petite taille moyenne). La figure 4.6 montre les temps d'exécution de PRINCE dans les deux cas : utilisation des listes prohibés (courbe "avec listes prohibées") ou non (courbe "sans listes prohibées"). Temps d'execution (en seconde) 1024 256 512 128 64 32 16 4 2 8 1 20
18 16 avec listes prohibees 14 Mushroom 12 10 8 6 4 2 Minsup (en %) FIG . 4.6 -- Effet de l'utilisation des listes prohibées sur les performances de PRINCE L'utilisation des listes prohibées permet
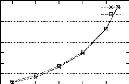
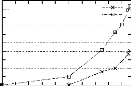
d'éviter l'exécution d'un grand nombre Comme dans le cas du premier type d'optimisation, cad la représentation compacte de la base, nous constatons que l'utilisation des optimisations relatives a la réduction du nombre de comparaisons réduit les temps d'exécution de PRINCE et s'adaptent aux caractéristiques différentes des bases. Il faut insister sur le fait, que pour chaque type d'optimisations (cad la représentation compacte de la base ou la réduction du nombre de comparaisons), les optimisations utilisées se complètent l'une l'autre et ne s'excluent pas mutuellement. 4.4 Effets de la variation de la mesure minconf Dans cette section, nous allons tester, pour une base donnée, l'effet de la variation de la mesure minconf sur les performances de PRINCE. La version utilisée dans ce test ainsi que dans les expérimentations présentées dans le reste du chapitre est une version dans laquelle toutes les optimisations sus-décrites sont implémentées. Pour évaluer l'effet de la variation de la valeur de minconf, nous considérons deux cas extremes a savoir le cas oft la valeur de minconf est égale a 0 (cad que toutes les regles génériques sont valides) et le cas oft la valeur de minconf est égale a 1 (cad que seules les regles génériques exactes sont valides). Pour réaliser ce test, nous avons choisi les bases CHESS et T40I10D100K étant donné le nombre élevé de regles valides extraites de ces bases si la valeur de minconf est égale a 0 et pour de faibles valeurs de minsup. La figure 4.7 montre les temps d'exécution de notre algorithme sur ces deux bases pour une valeur de minconf égale a 0 et pour une valeur de minconf égale a 1. FIG . 4.7 -- Effet de la variation de minconf sur les performances de PRINCE
1024 512 Temps d'execution (en seconde) 512 256 256 128 Temps d'execution (en seconde) 128 64 32 64 16 32 8 16 4 8 2 4 1 2 90 0.5 50 60 70 80 Chess minconf=0 40 Minsup (en %) T40I10D100K minconf=0 9.5 8.5 7.5 6.5 5.5 4.5 3.5 2.5 1.5 Nous constatons que la variation de la valeur de minconf n'a pas de conséquence significative sur les performances de PRINCE pour les bases CHESS et T40I10D100K. Ce résultat n'est pas restreint a ces deux bases mais est généralisable pour toutes les bases testées. En effet, tout au long de nos expérimentations, nous avons constaté qu'étant donné le treillis des générateurs minimaux construit, la troisième étape (cad la procédure GEN-BGRS page 53) constitue l'étape la moins cofiteuse dans notre algorithme. De plus, la modification dans les valeurs de minsup et celles de minconf, pour une valeur fixée de minsup, n'a pas une influence significative sur les temps d'exécution de cette étape. |