II- Analyse analytique
Application du test de Dickey- Fuller Augmenté
(DFA)
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série IEV.
Remarque
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz.
s Modèle [3]
d
A = + + + A + .
IEV IEV ? c fi t Çb IE V e
t 1 j t j t
?
j
?
1
Avec et est un processus stationnaire.
On commence par tester la significativité de la tendance
en se référant aux tables de DickeyFuller. Le résultat du
test de la série IEV est donné dans la table
suivante:
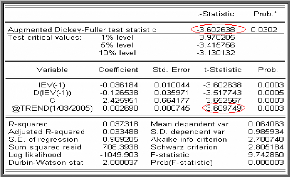
On compare la t-statistique du coefficient de la tendance
(@trend) avec la valeur donnée par la table de Dickey-Fuller. La
tendance est significativement différente de zéro puisque sa t -
statistique (3,609) est supérieure à la valeur critique (2,78),
au seuil statistique 5%. De plus la statistique de Student t?à
= -3,6026 est inférieure a la valeur critique -3,415 (donnée par
la
table de Dickey- Fuller) pour le seuil 5%.
D'où la série ne possède pas une racine unitaire (on
rejette l'hypothèse nulle «q$ = 0«).
Donc la série IEV est non stationnaire de
type TS, pour la stationnariser on a eu recours à un
ajustement linéaire, car le R2 associé est égal
à 0.953.
|
Dépendent
|
MTH
|
RSQ
|
D.F
|
F
|
SIGF
|
b0
|
b1
|
b2
|
b3
|
|
IEV
|
LIN
|
0,953
|
758
|
15247,1
|
0
|
65,81
|
0,0724
|
|
|
|
IEV
|
LOG
|
0,639
|
758
|
1341,57
|
0
|
13,2503
|
|
|
|
|
IEV
|
INV
|
0,143
|
758
|
34,16
|
0
|
-74,217
|
|
|
|
|
IEV
|
QUA
|
0,962
|
757
|
9513,65
|
0
|
0,045
|
3,60E-05
|
|
|
|
IEV
|
CUB
|
0,972
|
756
|
8801,92
|
0
|
73,7256
|
-0,0247
|
0,0003
|
-2, E-07
|
|
IEV
|
COM
|
0,961
|
758
|
18657,8
|
0
|
1,0008
|
|
|
|
|
IEV
|
POW
|
0,674
|
758
|
1569,13
|
0
|
0,1454
|
|
|
|
Remarque
On note la série ajustée par AJIEV
elle est donnée par la formule suivante :
AJIEV = IEV - y(t)
Où y(t) est l'équation de la
tendance.
Estimation de la tendance
L`estimation de l'équation d'ajustement
y(t) qui est donnée par l`équation suivante
:
y(t)=b0+b1
t
Les coefficients bo, b1
sont données par le tableau ci-dessus : D'où l`équation de
la
tendance est la suivante :
y(t)=65,81+0,0724 t
Graphe de l'ajustement linéaire de la série
IEV
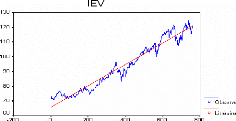
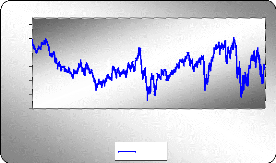
Diagramme séquentiel de la série
ajustée AJIEV
-12
12
-4
-8
4
8
0
1 76 151 226 301 376 451 526 601 676 751
AJ IEV
D'après le graphe on constate que la série
AJIEV semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Test de Dickey- Fuller Augmenté sur la
série AJIEV
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série AJIEV.
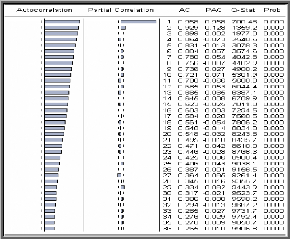
Corrélogramme de la série AJIEV
On remarque que la fonction d`autocorrélation de la
série AJIEV décroît rapidement vers
zéro et la première autocorrélation partielle est
hautement significative. Cette structure est peut être celle d`une
série stationnaire.
On va confirmer cette affirmation a l`aide du test de
Dickey-Fuller et du test de Fisher.
Test de Dickey- Fuller Augmenté sur la
série AJIEV
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [4], [5] et [6] de
Dickey-Fuller sur la série AJIEV.
Modèle [6]
d
.
? = + + â + A +
AJIEV çb AJIE V ? c t çb AJIEV
e
t t 1 j t j t
?
j
?
1
Avec et est un processus stationnaire.
On vérifie alors l'absence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat du test pour la
série AJIEV est donnée par la table suivante
:
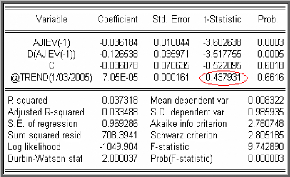
On remarque que la t- statistique de la tendance (= 0,43 79) est
inférieure aux valeurs critiques 3,48; 2,78 et 2,38 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et10%, on
le confirme par la probabilité = 0,6616 supérieure à
0,05.
Donc la tendance n'est pas significativement différente de
zéro.
Modèle [5]
d
A = + + ? A +
AJIEV A JIE V ? AJIE V E
C .
t t j t j t
1 ?
?
1
j
Après rejet du modèle [6], on procède au
test d'absence de la constante, dont le résultat est donné par la
table suivante :
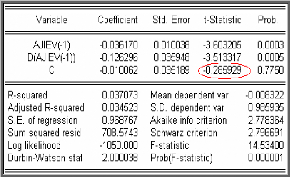
On remarque que la t-statistique de la constante (= -0.2859) est
inférieure aux valeurs critiques 3,72; 3,08 et 2,72 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et 10%, on
le confirme par la probabilité 0,775 supérieure à 0,05.
Donc la constante n'est pas significativement différente
de zéro.
Modèle [4]
d
A = ? ? A ?
A J IE V q$ A J IE V q$ A J IE V ?
t t j t j t .
-1 -
j=1
On teste la présence d'une racine unitaire dans le
processus en testant la nullité du paramètre q$ à
l'aide d'une statistique de Student, où q$à
désigne l'estimateur des moindres carrés
ordinaires (MCO).
Le résultat du test pour la série
AJIEV est donné dans le tableau suivant :
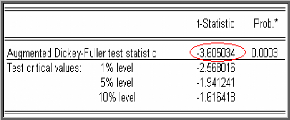
La statistique de Student (t?à = -3,650) est
inférieure aux valeurs critiques -2,5680; -1,9412
et -1,6164 pour les seuils 1%, 5% et 10% , d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série AJIEV
Table de l'ANOVA
|
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
F
|
Probabilité
|
Valeur critique pour F
|
|
Lignes
|
8945,18746
|
151
|
59,2396521
|
61,524
|
1,942E-289
|
1,226
|
|
Colonnes
|
2,05511717
|
4
|
0,51377929
|
0,534
|
0,71110566
|
2,386
|
|
Erreur
|
58 1,573868
|
604
|
0,96287064
|
|
|
|
|
Total
|
9528,81645
|
759
|
|
|
|
|
Test d'influence de facteur colonne, la période
(jours : H0 = pas d'influence)
Fs tat = 0,534
<Ftheo = 2,386 donc on accepte
l'hypothèse nulle ; la série n'est pas saisonnière.
Test de l'influence du facteur ligne, la tendance
(H0 =pas d'influence du
facteur
semaine)
F?c
= 61,524 > tabF? = 1,226 donc (on rejette
l'hypothèse nulle) la série est peut être affectée
d'une tendance.
En conclusion la série AJIEV est donc stationnaire, c'est
à dire intégrée d'ordre 0. Estimation des
paramètres de modèle
Il convient à présent d'estimer le modèle
susceptible de représenter la série. En observant les
corrélogrammes simple et partiel de la série stationnaire AJIEV,
nous remarquons que la fonction d'auto corrélation simple (AC)
possède des valeurs importantes aux retards q=1, 2, 3, 4, 5...
; et la fonction d'auto corrélation partielle (PAC)
possède des valeurs importantes aux retards p=1,2 et 4 .
Par conséquent nous avons plusieurs
modèles candidats parmi lesquels nous avons sélectionné
deux modèles :
|
Modèles
|
AIC
|
BIC
|
|
ARMA (1, 1)
|
2,77
|
2,78
|
|
ARMA (4, 2)
|
2,77
|
2,79
|
On a choisi le modèle parcimonieux qui minimise les deux
critères AIC et BIC qui est le modèle ARMA (1,
1).
Estimation du processus ARMA (1,1)
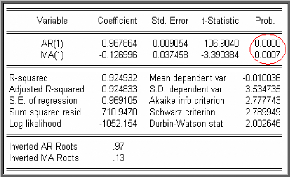
Test de validation des paramètres
On remarque que tous les paramètres du modèle sont
significativement différents de zéro. En effet les statistiques
de Student associées sont en valeur absolue supérieurs à
1,96, ce qui est confirmé par les probabilités de
nullité des coefficients qui sont toutes inférieures à
0,05.
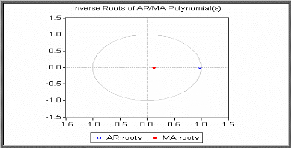
Graphique des inverses des racines
D'après la représentation graphique des inverses
des racines des polynômes de retards moyenne mobile et
autorégressif nous constatons qu'ils sont tous les deux
supérieurs à 1 en module (leurs inverses sont en module,
inférieures à 1).
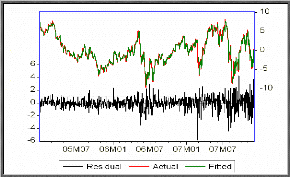
Graphique des séries résiduelles
réelles et estimées
La représentation graphique des séries
résiduelles réelles et estimées fait ressortir que le
modèle estimé ajuste convenablement la série AJIEV.
Il convient maintenant d'analyser les résidus à
partir de leur fonction d'autocorrélation et d'appliquer une
série de tests.
Tests sur les résidus du modèle
optimal
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
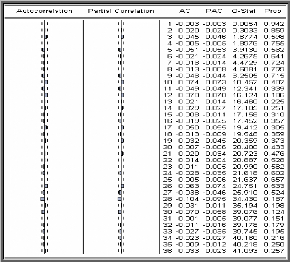
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 1, q = 1, P = 0 et Q = 0
égale à 83,488 est inférieure à 2
?0., 95 (97) = 120,99 ; on conclut alors que les
erreurs ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test des points de retournements
n -- 2
|
Le nombre des points de retournements égal à P =
?
|
Xi = 520
|
i ? 1
On a : n = 759 donc 2
E P n et VAR P --
16 29 n
( ) ( 2) 504,66 ( ) 134, 61
? -- = = =
3 90
VAR ( P ) = 11,56 , ( ) 2,01.
P E P
--
S ? = Donc :
Var P
( )
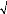
S = 1,32< S (tabulée) = 1,96
Alors, on accepte l'hypothèse H0 :
« les résidus sont aléatoires ».

12 ?
fi1
s Test de nullité de la moyenne des
résidus

|
D'après le Tableau ci-dessus on a :
|
t = 0,156 qui est inférieure à 1,96 ;
Donc on accepte
|
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement) Après calculs nous avons obtenu :

6
N
71
?
24
Test de Skewness:
Test de Kurtosis :
0= 7,87 > 1, 96.
3 = 19,56 > 1,96.
N
Alors : les résidus ne sont pas gaussiens. Ce qui est
confirmé par le test de Jarque et Bera.
· Test de Jarque et Bera
D'après le tableau la statistique de Jarque et Bera
(notée S) est égale à 464,095; elle est
supérieure à (2)
? = 5,99. On conclue que les résidus forment un
bruit blanc non gaussien.
2
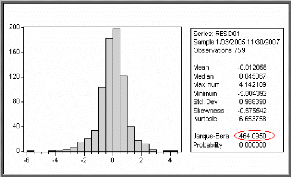
· Test QQ-Plot (méthode
graphique)
On remarque que le nuage de point n'est pas rectiligne sur la
droite, donc l'hypothèse nulle est rejetée c'est-à-dire
les résidus ne suivent pas une loi normale.
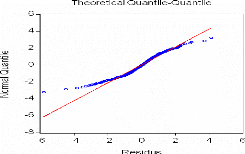
Test d'homoscédasticité
· Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante alors que
sa variance change au cours du temps. De plus le processus étant non
gaussien, on suspecte la présence d'un effet ARCH.
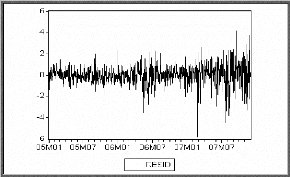
Corrélogrammes simple et partiel des
résidus carré
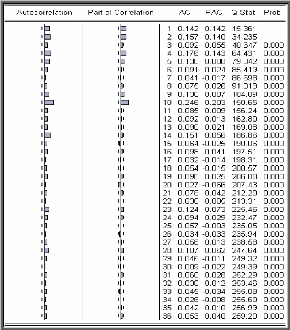
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il ya
certainement un effet ARCH. Pour cela on est passé au test d'effet ARCH
dont les résultats sont sur le tableau ci-dessous :
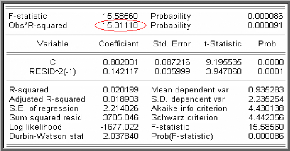
On a la statistique du multiplicateur de Lagrange
n*R2 (= 15,31) qui est supérieure à z2 (1) =
3,84, on rejette l'hypothèse nulle d'homoscédasticité en
faveur de l'hypothèse alternative
d'hétéroscedasticité conditionnelle.
Identification du modèle de type ARCH
On a eu plusieurs modèles avec des ordres p assez grands.
Par conséquent on opte pour le modèle GARCH (1,1).
Les résultats obtenus dans la table ci-dessus montrent
que les paramètres de l'équation de la variance conditionnelle
sont significativement différents de zéro.
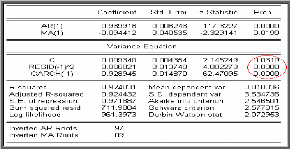
Le modèle retenu avec erreur GARCH (1, 1) s'écrit
sous la forme suivante :
(1 0, 97 ) (1 0, 09 )
+ = --
B Ajiev B
t
g
= h :
IID
t t t ? 1 t
= + +
0, 009 0, 066 0, 928
g 2
h h
t t t
? ?
1 1
?
? ?
? ?

( )
0, 1
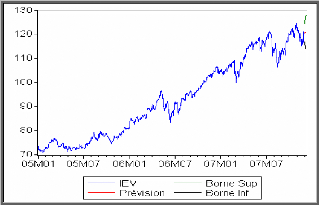
Prévision :
Pour faire des prévisions, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
On obtient par la suite
Observation
|
Prévision
|
Valeur réelle
|
Borne Inf
|
Borne Sup
|
761
|
120,51
|
116,80
|
116,88
|
124,16
|
762
|
120,60
|
116,10
|
115,77
|
125,44
|
763
|
120,68
|
117,05
|
114,95
|
126,42
|
764
|
120,77
|
118,29
|
114,30
|
127,23
|
765
|
120,85
|
117,99
|
113,77
|
127,93
|
|
Graphe de la série réelle et la
série prévue
Modélisation de la série
QQQQ
Notation
La série QQQQ est l'actif qui correspond à la
valeur des actions des cents plus grandes compagnies innovantes, autres que
financières, américaines et internationales cotées au
NASDAQ. Les cents plus grandes compagnies sont déterminées par
leur capitalisation sur le marché américain NASDAQ.
Identification
Les données de la série QQQQ s'étalent sur
une période de trois ans, les observations sont journalières ; du
03 janvier 2005 au 30 novembre 2007 soit 760 observations. L'unité de
mesure est le dollar américain.
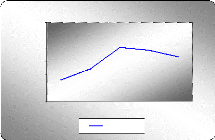
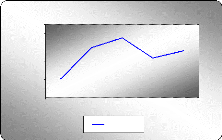
I- Analyse graphique
Graphe de la moyenne et la variance de la série
brute QQQQ
D'après les deux graphes ci-dessous on peut remarquer que
la moyenne et la variance varient au cours du temps, on peut donc
appréhender la non stationnarité de cette série.
Pour vérifier ceci, on va appliquer des tests
statistiques juste après la présentation des
corrélogrammes simple et partiel de la série brute.
21,75
21,25
20,75
20,25
21,5
20,5
22
21
20
1 2 3 4 5
QQQQ
VARIANCE
QQQQ
42
41,95
41,9
41,85
41,8
41,75
41,7
1 2 3 4 5
MOYENNE
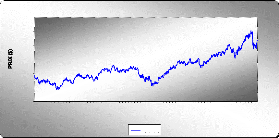
Diagramme séquentiel de la série brute
QQQQ
On voit clairement sur le graphe de la série brute que ce
processus est non stationnaire et cela provient tout naturellement de la
présence d'une tendance haussière.
60
55
50
45
40
35
30
1 71 141 211 281 351 421 491 561 631 701
GRAPHE DE LA SERIE BRUTE QQQQ
TEMPS (JOURS)
QQQQ
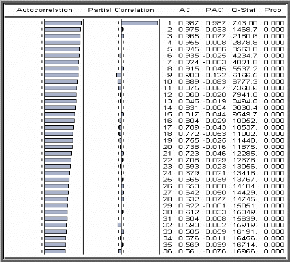
Examen du corrélogramme de la série
QQQQ
On constate que la fonction d'autocorrélation simple
(colonne AC) décroît très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seulement son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés)
II -Analyse analytique
Application du test de Dickey- Fuller Augmenté
à la série QQQQ
On procède à l'estimation par la méthode
des moindres carrés des trois modèles (1), (2) et (3) de
Dickey-Fuller sur la série QQQQ.
Remarque
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz.
s Modèle [3]
d
.
A = + + â + >JJ A +
Q Q Q Q q$ Q Q Q Q c t Q Q Q Q
q$ e
t -1 j t j t
-
j
?
1
Avec et est un processus stationnaire.
On vérifie la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat pour la série
QQQQ est donné dans la table suivante :
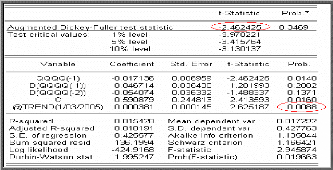
On voit que la probabilité 0.0088 < 0.05,
l`hypothèse nulle est rejetée : la tendance est significativement
différente de zéro, de plus la statistique de Student
t?à = -2.46
est supérieure a la valeur critique -3.4157
(donnée par la table de Dickey- Fuller) pour le seuil
5%. D'où la série possède une racine unitaire (on accepte
l'hypothèse nulle «q$ = 0«).
Donc la série QQQQ est non stationnaire
de type TS et DS en même temps, pour la
stationnariser on a eu recours à une différentiation d'ordre
1.
Notation : On note la série
différenciée par DQQQQ, elle est donnée par la formule
suivante :
DQQQQ t = QQQQ t -QQQQ t-1 .
Diagramme séquentiel de la série
différenciée DQQQQ
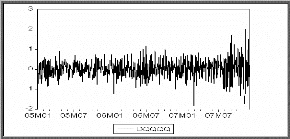
D'après le graphe on constate que la série
DQQQQ semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Corrélogramme de la série
DQQQQ
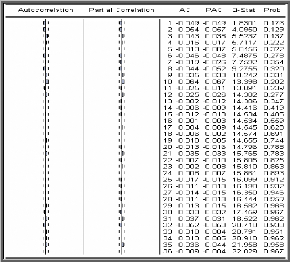
On voit que toutes les autocorrélations sont non
significativement différentes de 0 ( toutes les p-values sont
supérieures à 0,05), ce qui mène à dire que le
processus DQQQQ forme un bruit blanc.
On va confirmer cette affirmation a l`aide du test de
Dickey-Fuller et du test de Fisher.
Test de Dickey- Fuller Augmenté sur la
série DQQQQ
On procède à l'estimation par la méthode
des moindres carrés des trois modèles [4] [5] et [6] de
Dickey-Fuller sur la série DQQQQ.
Modèle [6]
d
t .
A ? ? ? â ? ? ? .
DQQQQ ? DQQQQ c t DQQQQ
t t ? ? e
1 j t j
-
Avec et est un processus stationnaire.
On vérifie l'absence de la tendance dans le processus en
testant la nullité du coefficient de la tendance
â. Le résultat du test pour la
série DQQQQ est donné par la table suivante :
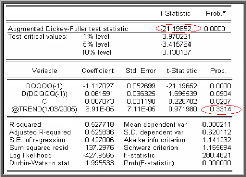
A = + ? A +
DQQQQ I DQQQQ ? I DQQQQ E
t t j t j
1 ?
j
.
t
? 1
On remarque que la probabilité de la tendance (= 0,3314)
est supérieure à 0,05 ; donc la tendance n'est pas
significativement différente de zéro.
Modèle [5]
d
A = + + A +
.
DQQQQ I DQQQQ c I DQQQQ E
t t j t j t
-1 -
j
?
1
Après rejet du modèle [6], on procède au
test d'absence de la constante, dont le résultat est donné par la
table suivante :
On remarque que la probabilité de la constante (= 0,2
167) est supérieure à 0,05 ; Donc la constante n'est pas
significativement différente de zéro.
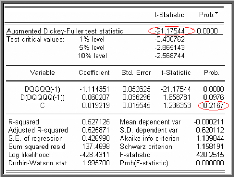
Modèle [4]
d
On teste alors la présence d'une racine unitaire dans le
processus en vérifiant la nullité du paramètre q$
à l'aide d'une statistique de Student, où
q$à désigne l'estimateur des moindres
carrés ordinaires (MCO).
Le résultat du test pour la série DQQQQ est
donné dans le tableau suivant :
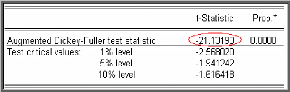
La statistique de Student (t?à = -21,13193) est
inférieure aux valeurs critiques -2,5680; -
1,9412 et -1,6164 pour les seuils 1%, 5% et 10%, d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série DQQQQ
TABLE de l'ANOVA
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
Fc
|
Probabilité
|
Valeur critique pour F
|
Lignes
|
26,1151955
|
150
|
0,174101303
|
0,942
|
0,66708202
|
1,226
|
Colonnes
|
1,27794251
|
4
|
0,3194855629
|
1,729
|
0,14191837
|
2,386
|
Erreur
|
110,864057
|
600
|
0,184773429
|
|
|
|
Total
|
138,257195
|
754
|
|
|
|
|
|
Test d'influence de facteur colonne, la période
(jours : H0 = pas d'influence)
Fc = 1,729 <Ftheo = 2,386 donc
on accepte l'hypothèse nulle ; la série n'est pas
saisonnière.
Test de l'influence du facteur ligne, la tendance
(H0 =pas d'influence du
facteur
semaine)
statF? = 0,942 < theoF? = 1,226 donc (on
rejette l'hypothèse nulle) la série n'est pas affectée
d'une tendance.
Conclusion
La série DQQQQ est donc stationnaire et se comporte comme
un bruit blanc, passons aux tests pour le confirmer.
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
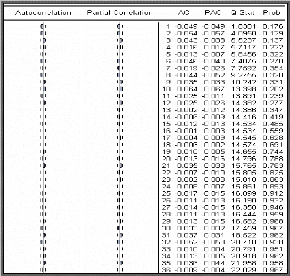
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 0, q = 0, P = 0 et Q =0 égale
à 62,97 est inférieure à 2
?0., 95 (99) = 123,23; On conclue alors que les
erreurs ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test de la nullité de la moyenne des
résidus
Si t < tn_1 à
5% (=1,96), on accepte l'hypothèse de nullité de la moyenne des
résidus.
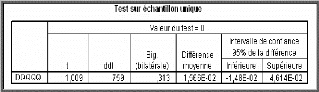
D'après le Tableau ci-dessus on a :
t = 1,009 qui est inférieure à 1,96 ; Donc on accepte

12 ?
fi1
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement)

71
6
N
?
24
Test de Skewness:
Test de Kurtosis :
0= 1,6 < 1, 96.
3 = 10,85> 1,96.
N
Alors, les résidus ne sont pas gaussiens. Ce qui est
confirmé par le test de Jarque et Bera
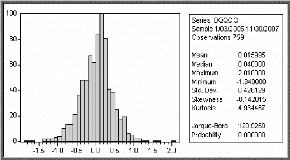
· Test de Jarque et Bera :
D'après le tableau la statistique de Jarque et Bera
notée (S) est égale à 121,2207 ; elle est
supérieure à (2)
? = 5,99. On conclue que les résidus forment un
bruit blanc non gaussien.
2
· Test QQ-Plot (méthode graphique)
:
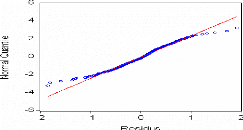
Donc l'hypothèse nulle est rejetée, les
résidus ne sont pas gaussiens.
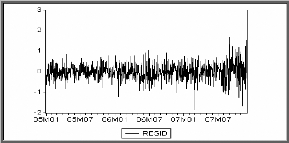
Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante alors que
sa variance change au cours du temps. De plus le processus étant non
gaussien, on suspecte un effet ARCH.
Corrélogrammes simple et partiel des
résidus au carré
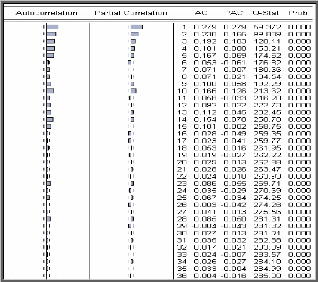
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il y a
certainement un effet ARCH. Pour cela on est passé au dont les
résultats sont sur le tableau suivant :
|
H
|
Pvalue
|
T-Stat
|
Critical value
|
|
1
|
0
|
59,1448
|
3,8415
|
|
1
|
0
|
77,9396
|
5,9915
|
|
1
|
0
|
84,8244
|
7,8147
|
D'après le test H=1, les P-value sont nulles et les T-Stat
sont supérieures aux valeurs critiques, donc on rejette
l'hypothèse nulle, c'est-à-dire qu'il existe un effet ARCH.
Identification du modèle de type ARCH
Les résultats obtenus dans la table ci-dessus montrent que
les paramètres de l'équation de la variance conditionnelle sont
significatifs de zéro.
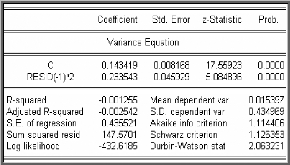
Le modèle retenu est ARIMA(0, 1, 0) avec erreur ARCH (1)
s'écrit sous la forme suivante :

E 17 17
t t t
? h IID
t :
( )
0, 1
L
?
? ?
? ?
( )
1 -- B
2
= +
0,14340,2335 E ?
t t
1
h
GLD
t t
? E
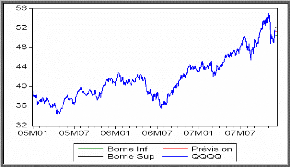
Prévision
Pour faire la prévision, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
On a par la suite
|
Observation
|
Prévision
|
Valeur réelle
|
Borne Inf
|
Borne Sup
|
|
761
|
51,04
|
50,79
|
50,506
|
52,082
|
|
762
|
51,7
|
50,58
|
50,489
|
52,155
|
|
763
|
52,43
|
51,49
|
50,479
|
52,168
|
|
764
|
52,44
|
52,22
|
50,474
|
52,168
|
|
765
|
52,65
|
52,23
|
50,474
|
52,169
|
Graphe de la série réelle et la
série prévue
85,00
80,00
75,00
70,00
65,00
60,00
55,00
50,00
45,00
40,00
35,00
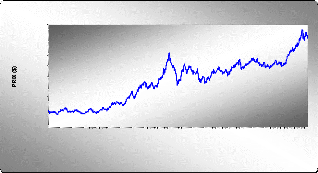
1 56 111 166 221 276 331 386 441 496 551 606 661 716
GRAPHE DE LA SERIE BRUTE GLD
TEMPS (JOURS)
Modélisation de la série GLD
Notation
La série GLD est l'actif qui correspond à la valeur
de l'OR sur les marchés internationaux.
Identification
Les données de la série GLD s'étalent sur
une période de trois ans, les observations sont journalières ; du
03 janvier 2005 au 30 novembre 2007 soit 760 observations. L'unité de
mesure est le dollar américain.
I- Etude de la stationnarité
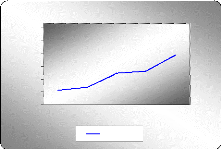
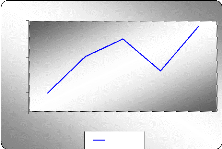
Graphe de la moyenne et de la variance de la série
brute GLD
114
113
112
111
110
109
1 2 3 4 5
GLD
VARIANCE
GLD
57,66
57,55
57,44
57,33
57,22
57,11
57
1 2 3 4 5
MOYENNE
D'après les deux graphes, on remarque que la moyenne et la
variance varient au cours du temps. On peut donc dire que cette série
semble non stationnaire.
Pour vérifier ceci, on va appliquer des tests statistiques
justes après la présentation des corrélogrammes simple et
partiel de la série brute.
Diagramme séquentiel de la série brute
GLD
D`après le graphe la série a une tendance
haussière, elle n`est donc pas stationnaire. Elle a aussi un
corrélogramme qui a une structure particulière.
La représentation graphique fait ressortir une tendance
qu'il faut confirmer ou infirmer à l'aide du test de l'analyse de
variance et de Dickey-Fuller respectivement.
Examen du corrélogramme de la série
GLD
Nous constatons que la fonction d'autocorrélation simple
(colonne AC) décroît très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seul son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés).
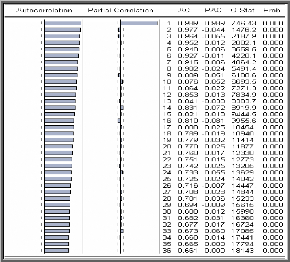
-Corrélogramme de la série GLD-
II- Application du test de Dickey- Fuller Augmenté
a la série GLD
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série GLD.
Remarque :
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz. Modèle [3]
.
d
A = 1 + + + ? A +
GLD GLD c â t GLD
çb ? çb ?
t j t j t
?
j ? 1
Avec e t est un processus stationnaire.
On teste alors la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat de l'affichage pour la
série GLD est donné dans la table
suivante :
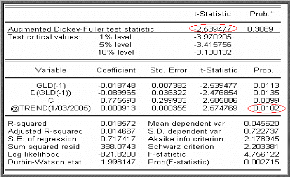
On compare la t-statistique du coefficient de la tendance
(@trend) avec la valeur donnée par la table de Dickey-Fuller. On voit
que la probabilité 0.0 10 < 0.05, l`hypothèse nulle est
rejetée : la tendance est significativement différente de
zéro, de plus la statistique de Student t?à = -2.539 est
supérieure a la valeur critique -3.4157 (donnée par la table
de Dickey-
Fuller) pour le seuil 5%. D'où la
série possède une racine unitaire (on accepte l'hypothèse
nulle «q$ = 0«).
Donc la série GLD est non stationnaire de
type TS et DS en même temps, pour la
stationnariser on a eu recours à une différentiation d'ordre
1.
Notation : On note la série
différenciée par DGLD, elle est donnée par la formule
suivante :
DGLD t = GLD t -GLD t-1.
Diagramme séquentiel de la série
ajustée DGLD
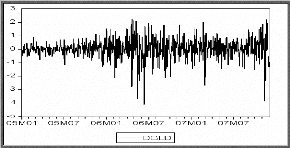
D'après le graphe on constate que la série
DGLD semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Corrélogramme de la série DGLD
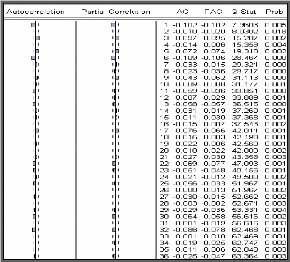
On remarque que la première autocorrélation simple
et partielle de la série DGLD est significativement différente de
0, pour cela on applique le test de Dickey-Fuller sur cette série
différenciée.
Test de Dickey- Fuller Augmenté sur la
série DGLD
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [4], [5] et [6] de
Dickey-Fuller sur la série DGLD.
Modèle [6]
.
d
A = + + â + J A +
DGLD Çb DGLD ? c t Çb DGLD e
t t 1 j t j t
j=1
?
Avec et est un processus stationnaire.
Nous testons alors la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat de l'affichage pour la
série DGLD est donné par la
table suivante :
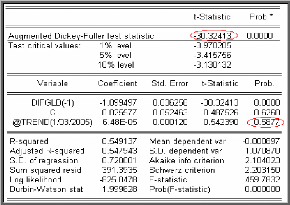
On remarque que la probabilité de la tendance (= 0,587)
est supérieure à 0,05 ; donc la tendance n'est pas
significativement différente de zéro.
Modèle [5]
d
.
A = + + A +
D G L D D G L D C D G L D
? Çb ?
t t 1 j t j t
?
j ? 1
On teste alors la présence d'une constante dans le
processus en testant la nullité du coefficient de la constante
C. Le résultat de l'affichage pour la série DGLD
est donné par la table suivante :
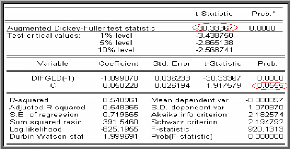
On remarque que la probabilité de la constante (= 0,055)
est supérieure à 0,05 ; Donc la constante n'est pas
significativement différente de zéro.
Modèle [4]
d
? ? ? ? ? ?
D G L D q$ D G L D ? q$ D G L D ?
t j t j t .
t 1 ?
j ? 1
On teste alors la présence d'une racine unitaire dans le
processus en testant la nullité du paramètre q$ à
l'aide d'une statistique de Student, où q$à
désigne l'estimateur des moindres
carrés ordinaires (MCO).
Le résultat de l'affichage pour la série
DGLD est donné dans le tableau suivant :
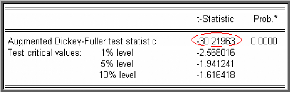
La statistique de Student t?à = -30,2196 est
inférieure aux valeurs critiques,-2,5680; -1,9412
et -1,6164 pour les seuils, 1%, 5% et 10%, d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série DGLD
Table de l'ANOVA
|
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
F
|
Probabilité
|
Valeur critique pour F
|
|
Lignes
|
77,223075
|
150
|
0,5148205
|
0,98
|
0,53130603
|
1,227
|
|
Colonnes
|
4,6413637
|
4
|
1,16034093
|
2,22
|
0,06512035
|
2,386
|
|
Erreur
|
313,09244
|
600
|
0,52182073
|
|
|
|
|
Total
|
394,95687
|
754
|
|
|
|
|
Test d'influence de facteur colonne (jours)
Fs tat = 2,22 <Ftheo = 2,386 donc on accepte
l'hypothèse nulle ; la série n'est pas saisonnière.
Test d'influence de facteur ligne (semaines)
statF? = 0,98 < theoF? =1,227 donc (on
rejette l'hypothèse nulle) la série n'est pas affectée
d'une
tendance.
En conclusion La série DGLD est donc stationnaire.
Il convient à présent d'estimer le modèle
susceptible de la représenter. En observant les corrélogrammes
simple et partiel de la série stationnaire DGLD, on remarque que la
fonction
d'auto corrélation simple (AC) possède des
valeurs importantes aux retards q= 1, 3, 5, 6; et la fonction d'auto
corrélation partielle (PAC) possède des valeurs importantes aux
retards p= 1, 3, 5, 6.
Par conséquent on a eu plusieurs modèles candidats
parmi lesquels on a sélectionné les deux modèles :
|
Modèles
|
AIC
|
BIC
|
|
ARIMA (4, 1, 4)
|
2,16
|
2,19
|
|
ARIMA (7, 1, 7)
|
2.16
|
2.22
|
On a choisi le modèle qui minimise les deux
critères AIC et BIC on retient le modèle ARIMA (4, 1,
4).
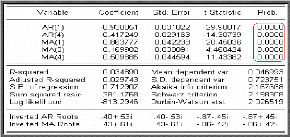
Estimation des paramètres de
modèle
Test de validation des paramètres
Nous remarquons que tous les paramètres du modèle
sont significativement différents de zéro. En effet les rapports
des coefficients du modèle sont en valeur absolue supérieurs
à 1.96, ce qui est confirmé par la probabilité de
la nullité des coefficients qui sont toutes inférieures
à 0.05.
Représentation graphique des inverses des
racines
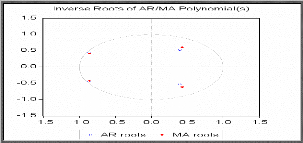
De la représentation graphique des inverses des racines
des polynômes de retards moyenne
mobile et autorégressif nous déduisons que les
racines sont toutes supérieurs à 1 en module
(leurs inverses sont en module, inférieures à
1). Représentation graphique des séries
résiduelles réelles et estimées
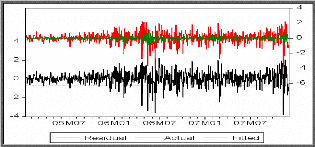
A partir de la représentation graphique des séries
résiduelles réelles et estimées on constate que le
modèle estimé ajuste bien la série DJGLD.
Il convient maintenant d'analyser les résidus à
partir de leur fonction d'autocorrélation et d'appliquer une
série de tests.
Tests sur les résidus du modèle
optimal
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
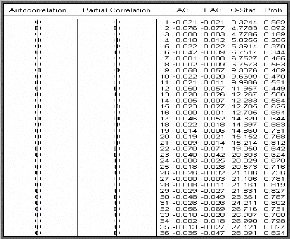
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 1, q = 0, P = 0 et Q =0 égale
à 84,9 est inférieure à 2
?0., 95 (98) = 122,11 ; on conclut alors que les erreurs
ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test des points de retournements
n - 2
|
Le nombre des points de retournements égal à P =
?
|
Xi = 503
|
i = 1
Nous avons : n = 759 donc 2
E P n et VAR P -
16 29 n
( ) ( 2) 504,66 ( ) 134,61
= - = = =
3 90
VAR ( P ) = 11,602 , ( ) 0,14
P E P
-
S = 0,14 < S (tabulée) = 1,96
S = = - . Donc :
Var P
( )
Alors, nous acceptons l'hypothèse H0 :
« les résidus sont aléatoires » s
Test de la nullité de la moyenne des résidus
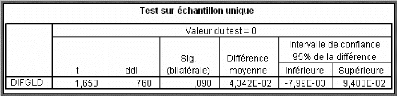
D'après le Tableau ci-dessus on a : t
= 1,658 qui est inférieure à 1,96 ; Donc on accepte
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
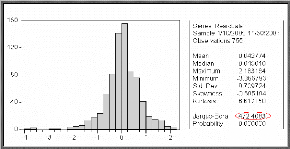
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement) :


12 ?
fi1
Après calculs on a obtenu :
71
Test de Skewness:
0 = 7,81>1,96.
6
N

24
Test de Kurtosis :
3 = 20,34 > 1,96.
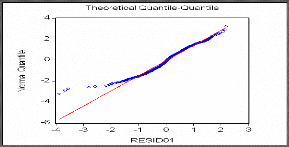
N
Test QQ-Plot (méthode graphique) :
Ainsi on rejette l'hypothèse de normalité, Ce qui
est confirmé par la statistique de Jarque et Bera notée (S) est
égale à 472,4083 qui est supérieure à (2)
? = 5,99. On conclut que les
2
résidus forment un bruit blanc non gaussien.
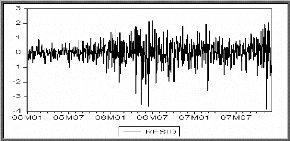
Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante (nulle)
alors que sa variance change au cours du temps. De plus le processus
étant non gaussien, on suspecte un effet ARCH
Corrélogramme simple et partiel des résidus
au carré
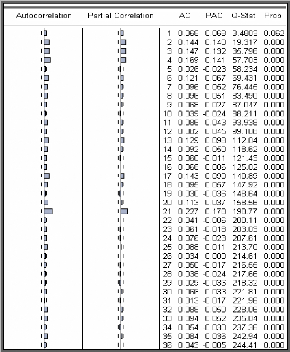
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il y a
certainement un effet ARCH. Pour cela on est passé au test dont les
résultats sont dans le tableau ci-dessous :
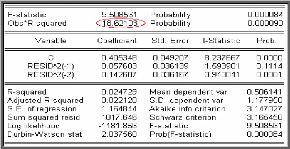
On a la statistique du multiplicateur de Lagrange n*R2
= 18,62 qui est supérieure à
z2 (2) = 5,99 alors on rejette l'hypothèse nulle
d'homoscédasticité en faveur de l'hypothèse
alternative d'hétéroscédasticité
conditionnelle.
Identification du modèle de type ARCH
On a eu plusieurs modèles candidats dont celui qui
minimise les critères AIC et BIC est le modèle ARCH (2).
Les résultats obtenus dans la table ci-dessus montrent que
les paramètres de l'équation de la variance conditionnelle sont
significativement différents de zéro.
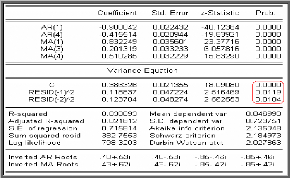
Le modèle retenu avec erreur ARCH (2) s'écrit sous
la forme suivante :

h t
0,386 0,118 0,123
+ +
& ? & ?
2 2
t t
1 1
& t
h 1l :
IID
t t t
? (
=
t
? ?
??
? & ll
1 0,9 0,41 1 (1 0,83 0,2 0 ,51 )
+ + -- = + + +
B B B GLD B B B
4 3 4
)( ) t
( )
0, 1
Prévision
Pour faire la prévision, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
|
Observation
|
Prévision
|
Valeur réelle
|
Born Inf
|
Borne Sup
|
|
761
|
76,95
|
78,28
|
75,29
|
78,63
|
|
762
|
76,98
|
79,4
|
75,49
|
78,48
|
|
763
|
76,63
|
78,63
|
75,13
|
78,13
|
|
764
|
76,89
|
79,37
|
75,42
|
78,37
|
|
765
|
76,8
|
78,6
|
75,34
|
78,27
|
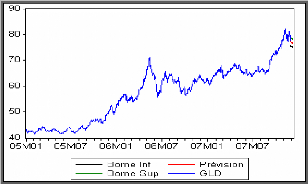
Graphe de la série réelle et la
série prévue
| 

