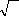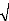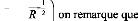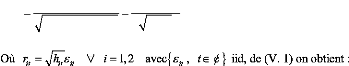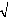implémentation d'une nouvelle méthode d'estimation de la matrice variance covariance basée sur le modèle GARCH multivarié, simulation par backtesting de stratégies d'investissement.( Télécharger le fichier original )par Khaled Layaida USTHB - Ingénieur d'état 2008 |

Chapitre 3 Lissage ExponentielI IntroductionLa prévision à court terme a connu des développements importants durant les dernières années; elle constitue la base de l'action. La prise de décision repose en effet toujours sur des prévisions. C'est ainsi qu'une entreprise commerciale s'intéresse aux prévisions des ventes futures pour faire face à la demande, gérer sa production ainsi que ses stocks, mais aussi orienter sa politique commerciale (prix, produits et marketing). De même, on essaie de prévoir les rendements d'un investissement, la pénétration d'un marché ou l'effet de la modération salariale sur l'emploi. Les développements de la pratique statistique ont permis de disposer d'un certain nombre d'outils de calcul, les méthodes de lissage exponentiel font l'objet de ce chapitre, ces méthodes datent du début des années soixante (HOLT en 1957 et BROWN en 1962). Ils justifient amplement leurs utilisations. Après avoir fait un lissage exponentiel simple qui ne peut être utilisé en présence d'une tendance ou d'une saisonnalité, nous passons au lissage double et à la méthode de HOLT, ces derniers peuvent convenir pour des séries présentant une tendance. Le lissage de WINTERS intervient dans les cas ou la tendance et la composante saisonnière sont juxtaposées soit de manière additive soit de manière multiplicative. II Principe de base La méthode de lissage exponentiel repose sur l'idée suivante : les informations contenues dans une série chronologique ont d'autant plus d'importance qu'elles sont plus récentes. Pour effectuer une prévision, il faut affecter aux informations un poids d'autant plus faible qu'elles proviennent d'époques plus éloignées. III Description de la méthode Si x1, x2 ,...; x n sont les termes d'une chronique, la méthode du lissage exponentiel consiste à prendre comme prévision : x = -- a x n + a x n -- h telle que 0 ? á ?1, h est l'horizon. $ $ n h (1 ) 1, , Où á, appelée constante de lissage est généralement comprise entre 0 et 1. Pour débuter le processus de lissage, il convient de choisir une valeur pour la constante. Ce choix est très important car il conditionne la prévision future à travers le degré de pondération que l'on affecte au passé récent et au passé lointain et ceci pour assurer une bonne qualité de prévision. IV Lissage exponentiel simple Cette méthode ne doit être employée que sur une série qui ne présente ni tendance ni De composante saisonnière. En prenant en compte toute l'histoire de la chronique de sorte que plus nous nous éloignons de la prévision moins l'influence des observations correspondantes est importante. Cette décroissance de l'influence est de type exponentiel ce qui justifie l'appellation. Nous disposons d'une série chronologique x =(x1,x2,...,x n ) de longueur enregistrée aux dates 1, . . ., n. Nous nous situons à la date n et nous souhaitons prévoir la valeur x n+h non encore observée à l'horizon h. Nous notons cette prévision : x $,n h . L'entier n est parfois appelé base de la prévision Les formules de lissage sont : x = -- a x n + a x -- telle que 0 ? á ?1 (*). Avec $ $ $ n h (1 ) 1, , n h x 1, h = x1, h (initialisation). Il existe d'autres initialisations x1 comme la moyenne de la série. Dans le choix de á, nous distinguons les deux cas particuliers suivants : ? Si á =0, alors toutes les prévisions sont identiques, les prévisions restent inchangées, on dit dans ce cas que le lissage est inerte. ? Si á =1, la prévision est égale à la dernière valeur observée, la nouvelle valeur lissée est toujours égale à la dernière réalisation, dans ce cas on dit que le lissage est hyper réactif. La relation (*) peut être développée en remontant dans le temps (n-1, n-2, n-3,..., 1 ,0) et laisse apparaître que la nouvelle valeur lissée est une combinaison linéaire de toutes les observations du passé affectée d'un poids décroissant avec l'âge, les poids sont de plus en plus faibles au fur et à mesure que l'on s'éloigne de l'observation actuelle. On retrouve : x $ a (1 ) , = -- ? n h a x j n j -- n -- 1 j 0 Remarque La formule, $ $ x = -- a x n + a x n --
h permet : , ? D'interpréter, x $,n h comme le barycentre de xn et de x $ n -- 1 , h affecté respectivement des masses (1-á) et á. ? D'interpréter le lissage comme une moyenne pondérée de la dernière réalisation et de la dernière valeur lissée. ? De réécrire cette formule sous la forme suivante : x x _ a x n x n h $ , $ 1, ( $ ) n h n h (1 ) 1, = + _ _ _ Le lissage apparaît comme le résultat de la dernière valeur lissée corrigée par une pondération de l'écart entre la réalisation et la prévision. ? Lorsque á est proche de 0 (a 0), la pondération s'étale sur un grand nombre de termes dépendant du passé, la mémoire du phénomène étudié est forte et la prévision est peut réactive aux dernières observations. ? Lorsque á est proche de 1 (a 1), les observations les plus récentes ont un poids prépondérant sur les anciens termes, la mémoire du phénomène étudié est faible et la prévision est très réactive aux dernières observations. On peut retrouver l'équation du lissage exponentiel en employant une approche très simple basée sur le concept de la fonction de prévision, telle que: x $ n , h ? a n ... ( *** ) Où an est une constante qui dépend de l'origine de prévision. On choisit an en utilisant un critère de moindres carrés pondérés, avec des coefficients de pondération décroissant exponentiellement quand on recule dans le passé, de la forme de j J3 , on l'appelle facteur d'escompte. En appliquant la prévision au passé de la série, l'erreur de prévision est la différencex n _ j _ a n . La somme des carrés des erreurs à minimiser est alors de la forme :
j~0 Egalons à zéro la dérivée par rapport
à n a de cette expression: ( ) ( ) = _ ? _ 2 j n n j n j~0 Ce qui entraîne l'équation : ? = ? J3 x _ a J3 j j n j n j j ~ ~ 0 0 Or ( ) 1 ? ? _ J3 J3 _ j 1 j~0 D'où a J3 J3 x $ ( ) ( ) ? _ ? 1 ** j n n j~ 0 L'expression (**) est exactement ce que nous avons trouvé pour la prévision x $,n h, (relation (*)) du lissage exponentiel simple tel que le facteur d'escompte â est remplacé par la constante de lissage á c'est-à-dire â =á Démonstration : x x x $ ( ) $ n h , = _ + 1 a a n n h _ 1, a x a n n n = _ + ( ) ( ) 1 d'après la relation * ** a a _ 1 x x e x e x _ = = = + $ $ n n n n n n
_ 1 a e a a n n n n = 1 ( )( ) _ + + a a _ 1 = _ + _ + e e a a a n n n n n a a a a a a a a e a n n n = _ + ? ( ) 1 si 0 alors : _ 1 ( ) 1 _ a a a e a n n n n ? + = + 1 1 y _ _ 0 1 < < a a e a avec n n n = + y _ 1 En conséquence, nous pouvons dire que le lissage exponentiel simple est justifié dans le cas d'une fonction de prévision constante, dans le contexte de moindres carrés pondérés, et elle ne sera vraiment constante que si l'on choisit un facteur d'escompte â égale à 1, ce qui correspond à á =1. V Choix du coefficient de lissage Pour débuter le processus de lissage, il convient de choisir une valeur pour la constante á, ce choix est très important car il conditionne la prévision future à travers le degré de pondération que l'on affecte au passé récent et au passé lointain. Diverses procédures d'estimation ont été établies, on s'intéresse à la méthode la plus classique qui consiste à retenir une valeur de á qui minimise l'écart entre la prévision et la réalisation sur la partie connue de la chronique. Pour optimiser le choix de la constante á, il suffit de : ? Choisir un des critères d'optimisation : le critère MSE (Mean square error ou moyenne des carrées des résidus) satisfait ce besoin. ? Choisir un ensemble de valeurs de á pour effectuer un balayage, par exemple les valeurs de 0 à 1 par pas de 0,1. ? Choisir la prévision initiale. ? Pour chaque valeur de á choisie, on effectue l'ensemble du lissage exponentiel par application des formules suivantes: Pour n=1 à N....faire xn .'i- --> en x $ n ; - a en --> fin. ? Choisir la valeur de á qui améliore aux mieux le critère MSE (celle qui fournit la plus petite moyenne des carrées des résidus). VI Lissage exponentiel double Les formules précédentes permettent de calculer une prévision pour des séries chronologiques stationnaires sans tendance, nous pouvons définir un lissage exponentiel double qui est utilisé en cas de série présentant une tendance. On part d'une fonction de prévision linéaire de la forme: ->i,h = >n + nh Notons que : i>n Et t>n sont des coefficients dépendant de n On cherche à déterminer les valeurs des deux paramètres par le critère des moindres carrées escomptes â, tel que le facteur d'escompte est remplacer par á c'est-à-dire â =á. VII Méthode de Holt-Winters Cette approche a pour but d'améliorer et de généraliser le Lissage Exponentiel Simple. Nous étudions plusieurs cas particuliers de cette méthode : - ajustement d'une droite affine (sans saisonnalité) - ajustement d'une droite affine plus une composante saisonnière - ajustement d'une constante plus une composante saisonnière Cette méthode est plus souple que le lissage exponentiel amélioré, dans la mesure où elle fait intervenir deux constantes â et y au lieu d'une á. Telle que 0 <â < 1 et 0 < y < 1 deux constantes fixées et les formules de mise à jour : =flxn+(1-fl)[>(n-1)+§(n-1)1 § = y[t(n)- t>(n -1)1+ (1- y)§(n - 1) La prévision prend la forme : x $ n , h= a$1+ ha2$(n)
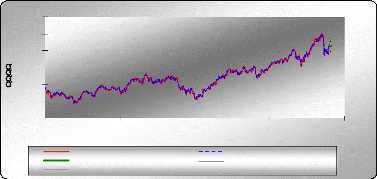
Si 2 1 ? a y = _ = 1 et _ a alors : 1 +a xn = ? _ + _ ? + _ 2 $( ) $( ) ( ) 2 a n a n a 1 2 1 1 1 ? ? a 2 ? ? $( ) $( ) ( ) 1 = _ + _ ? _ + _ _ ? a a n a n a n a n a n $( ) $( ) $( ) a 2 2 2 1 1 2 ( ) 1 _ a ? ? _ _ ? _ + _ ? ( ) $( ) $( ) 1 1 1 a 2 a n a n ? ? 1 2 2 $( ) ( ) 1 = _ + _ _ _ _ ? a n a n a n a n _ ? a 1 $( ) $( ) $( ) 2 1 1 2 1 1 ( ) 1 _ ? a ? Remarque Si â et y sont petits, le lissage est fort puisque á est grand et que nous tenons compte du passé lointain. Application : Lissage exponentiel Etude de la série QQQQ La série QQQQ est tendancielle et ne présente pas de composante saisonnière, donc dans ce cas on a appliqué la technique de lissage double. XLSTAT 2007 Séries temporelles Lissage : Holt-Winters Méthode : Linéaire (Holt) Alpha : Optimisé / Bêta: Optimisé Optimiser (Convergence = 0,0000 1 / Itérations = 500) Prédiction : 5 Intervalles de confiance (%) : 95 Statistiques simples
Coefficients d'ajustement (QQQQ)
Paramètres du modèle (QQQQ) Coefficient de lissage de la moyenne noté :
á= 0,952 La racine des carrés résiduels moyens : RMSE = 0,441
45 40 60 55 50 35 30 0 200 400 600 800 temps Holt-Winters(QQQQ) QQQQ Prédiction Borne inférieure (95%) Borne supérieure (95%) Holt-Winters / (QQQQ) Prévisions de la série QQQQ
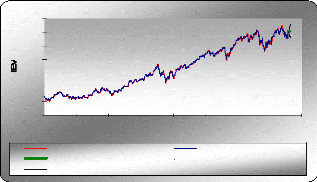
Graphe de la prévision Etude de la série IEV La série IEV est tendancielle et ne présente pas de composante saisonnière, donc dans ce cas on a appliqué la technique de lissage double. XLSTAT 2007 Séries temporelles Lissage : Holt-Winters Méthode : Linéaire (Holt) Alpha : Optimisé / Bêta: Optimisé Optimiser (Convergence = 0,0000 1 / Itérations = 500) Prédiction : 5 Intervalles de confiance (%) : 95 Statistiques simples
Coefficients d'ajustement (IEV)
Paramètres du modèle (IEV) Coefficient de lissage de la moyenne noté : á=0, 876 Coefficient de lissage de la tendance noté : /3 =0,067 La racine des carrés résiduels moyens : RMSE = 1,016
130 120 100 110 90 80 70 60 0 100 200 300 400 500 600 700 800 Holt-Winters(IEV) IEV Prédiction Borne inférieure (95%) Borne supérieure (95%) Holt-Winters / (IEV) temps Les prévisions de la série IEV
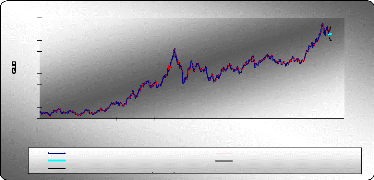
Graphe des prévisions Etude de la série GLD La série GLD est tendancielle et ne présente pas de composante saisonnière, donc dans ce cas on a appliqué la technique de lissage double. XLSTAT 2007 Séries temporelles Lissage : Holt-Winters Méthode : Linéaire (Holt) Alpha : Optimisé / Bêta: Optimisé Optimiser (Convergence = 0,0000 1 / Itérations = 500) Prédiction : 5 Intervalles de confiance (%) : 95 Statistiques simples
Coefficients d'ajustement (GLD)
Paramètres du modèle (GLD) Coefficient de lissage de la moyenne noté : á=0,905 Coefficient de lissage de la tendance noté : /3 =0,016 La racine des carrés résiduels moyens : RMSE = 0,726 Les prévisions de la série GLD
Graphe des prévisions
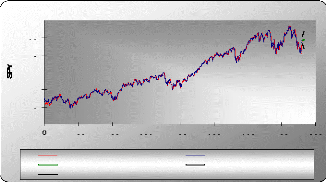
45 40 85 80 75 70 65 60 55 50 0 100 200 300 400 500 600 700 800 temps GLD Holt-Winters(GLD) Prédiction Borne inférieure (95%) Borne supérieure (95%) Holt-Winters / (GLD) Etude de la série SPY La série SPY est tendancielle et ne présente pas de composante saisonnière, donc dans ce cas on a appliqué la technique de lissage double. XLSTAT 2007 Séries temporelles Lissage : Holt-Winters Méthode : Linéaire (Holt) Alpha : Optimisé / Bêta: Optimisé Optimiser (Convergence = 0,0000 1 / Itérations = 500) Prédiction : 5 Intervalles de confiance (%) : 95 Statistiques simples
Coefficients d'ajustement (SPY)
Paramètres du modèle (SPY) Coefficient de lissage de la moyenne noté :
á=0,886 La racine des carrés résiduels moyens : RMSE = 1,054
160 150 140 130 120 110 100 Holt-Winters(SPY) SPY Prédiction Borne inférieure (95%) Borne supérieure (95%) 100 200 300 400 500 600 700 800 Holt-Winters / (SPY) temps Les prévisions de la série SPY
Graphe des prévisions Comparaison des méthodes Lorsqu'on adopte plusieurs méthodes de prévision sur une ou plusieurs chroniques, on est amené au bout du compte à les comparer afin de les départager en terme de qualité prévisionnelle, en se basant sur un certain nombre d'outils appelés « indicateurs de mesure de qualité prévisionnelle ». Ils en existent plusieurs, chacun sa procédure et ses propriétés, on à
MSE...etc. Dans notre cas, on utilise le RMSE = MSE avec : n n 1 1 2 MSE = ? = i (X Xà ) e 2 ? - i i n n i 1 = i 1 = : La distance au carré entre la valeur réelle et la valeur prédite ou bien l'erreur quadratique moyenne. La méthode jugée meilleure parmi d'autres est celle qui minimise le RMSE, qui signifie que la chronique est bien ajustée et que par conséquent les prévisions seront proches des réalisations. Comparaison du pouvoir prédictif de la méthode de Box-Jenkins et celui de Holt & Winters :
Table -1- Une méthode directe pour comparer l'efficacité des deux approches, consiste à comparer leur pouvoir prédictif, pour cela nous avons calculé les prévisions hors échantillon. Il en résulte que les modèles ARMA(1, 1, 1) et ARMA(3, 3) sont plus performant que celui des modèle Holt & Winter pour les séries IEV et SPY respectivement, par contre , les modèle Holt & Winter semble meilleur que les modèle ARIMA(0 ,1 ,0) et ARIMA(4, 1, 4) des séries QQQQ et GLD respectivement. Ce jugement a eu lieu grâce aux critères RMSE (voir Table -1-). Voici la Table-2- qui nous permet de visualiser les prévisions des quatre séries et leurs valeurs réelles avec les deux méthodes Box & Jenkins et Holt & Winters pour la période allant de 03 décembre 2007 au 07 Décembre 2007.
Table -2- Introduction L'approche ARCH/GARCH a été proposée pour prendre en compte des variances conditionnelles dépendant du temps. Le principe général consiste donc à remettre en cause la propriété d'homoscédasticité que l'on retient généralement dans le cadre du modèle linéaire. La spécification hétéroscédastique conditionnelle ou ARCH a été initiée par Engle (1982) Pour caractériser la dynamique des seconds moments conditionnels que l'on retrouve dans la Plupart des séries financières. Elle a été par la suite généralisée par Bollerslev (1986) avec ce qu'on a appelé l'hétéroscédastique conditionnelle autorégressive généralisée ou GARCH c'est le modèle le plus populaire lorsqu'il s'agit d'estimer les variances conditionnelles. Les modèles GARCH ne se contentent pas seulement d'estimer des variances qui évoluent dans le temps, mais incorporent également les caractéristiques observés sur les séries financières (leptokurtisme, clusters de volatilité,...). D'autres généralisations ont été proposées par plusieurs chercheurs, on peut citer les modèles AGARCH, EGARCH, FIGARCH, GJR-GARCH, TARCH,... I. Diverses Modélisations I.1 Modèle ARCH (q) Les économistes utilisent fréquemment des modèles estimés à l'aide des séries temporelles où la variabilité des résidus est relativement faible pendant un certain nombre des périodes successives, puis beaucoup plus grande pour un certain nombre d'autres périodes et ainsi de suite, et ce généralement sans aucune raison apparente, ce phénomène est particulièrement fréquent et visible avec les séries boursières, des taux des changes étrangers, ou d'autre prix déterminés, sur les marchés financiers, ou la volatilité semble généralement varier dans le temps. Récemment, d'importants approfondissements ont vu le jour dans la littérature pour modéliser ce phénomène. L'article novateur d'Engle (1992), expose pour la première fois le concept d'hétéroscédasticité conditionnelle autorégressive, ou ARCH. L'idée fondamentale est que la variance de l'aléa au temps t dépend de l'importance des aléas au carré des périodes passés, cependant il existe plusieurs façons de modéliser cette idée de base, la littérature correspondante est foisonnante. Définition : Un processus { E t , t Ecents } satisfait une représentation ARCH (q) si :
E t t t = 11 h q E E a 2 ? E h ( / ) t t t = = + ? 1 0 i ? 1 0, 0 1 , . . . , a ~ V = i i ? ? ? ? ?L > a 0 q a E a 2 , 0 , O ù ~ i t i q ? et (?t ) t désigne un bruit blanc faible tel que E(ii t ) = 0 et ( 2 ) 2 E 1 t = cr . Pour ce type de processus on retrouve les deux propriétés essentielles vues précédemment à savoir la propriété de différence de martingale E(E t /' t ? 1 ) = 0 et la propriété de variance conditionnelle variable dans le temps puisque : q i / I = = +? Var ( ) 2 E . h a a E t t t i t 1 0 ? i ? 1 Où It ? 1 est la tribu engendrée par le passé du processus jusqu'au temps t-1. I.2 Modèle GARCH (p, q) (Bollerslev [1986]) Introduction Plusieurs variantes du modèle ARCH ont été proposées. Une variante particulièrement utile est le modèle ARCH généralisé ou GARCH suggéré par Bollerslev (1986). Contrairement au modèle ARCH, la variance conditionnelle ht dépend aussi bien de ses propres valeurs passées que des valeurs retardées de 2 Et . Dans la pratique un modèle GARCH avec très peu de paramètres ajuste souvent aussi bien qu'un modèle ARCH ayant de nombreux paramètres, en particulier, un modèle simple qui fonctionne souvent très bien est le modèle GARCH (1, 1). On considère un modèle linéaire autorégressif exprimé sous la forme suivante : Xt =E(X t /X t ? 1)+E t Où { E t , t E cents } est un bruit blanc faible tel que E (Et) = 0 et E ( E t E s ) = 0 sit ~ s, satisfaisant la condition de différence de martingale. E(EtIt?1 ) = 0 On suppose toujours que le processus peut s'écrire sous la forme :
E t =? tht Où i't est un bruit blanc On cherche à modéliser la volatilité conditionnelle du processus de bruit { E t , t E cents } pour tenir compte de la dynamique observée, on peut être amené à imposer une valeur élevée du paramètre q dans la modélisation ARCH (q) ce qui peut poser des problèmes d'estimation. II s'agit d'une difficulté semblable à celle que l'on rencontre dans les modélisations de l'espérance conditionnelle: si le théorème de Wold assure que toute série stationnaire possède une représentation de type MA, il est possible que pour une série donné, l'ordre de cet MA soit particulièrement élevé, voir infini. Dans ce cas Box et Jenkins proposent de regagner en parcimonie en utilisant une représentation de type AR (p) ou ARMA (p, q). Pour la variance conditionnelle, Bollerslev (1986) définit ainsi le processus GARCH (p, q). Définition : Un processus { e t , t E cents } satisfait une représentation GARCH (p q) si : ??
e ii t t t = h = + ? + ? q p t t 2 ( ) où est un bruit blanc ij h h t i t i j a a e - /3 - 0 t j i j = = 1 1 avec les conditions a0 > 0, ai ~ 0 /3j ~ 0 Vi = 1,..., q, Vj = 1,..., p suffisante pour garantir la positivité deht . Ainsi l'erreur du processus{ X t , t E cents } définie par le processus GARCH(p, q) admet pour moments conditionnels : E( e t / e t - 1) = 0 q p Var e - h a a e /3 e ( ) 2 t t t i t i j t j / ' = = + ? + ? 1 0 - - i j = = 1 1 Tout comme le modèle ARCH, on peut exprimer le processus 2 et sous la forme d'un processus ARMA défini dans une innovation. u t = e t - h t 2 En introduisant cette notation dans l'équation d'un GARCH (p, q), il dévient : max( , ) p qp e a a /3 e /3 e u 2 ( ) ( ) 2 2 t t - = + + + ? - u 0 i i j t j t j t i - - - i = 1 j = 1 D'où l'on tire que: p max( , ) p q e a a /3 e u /3 u 2 = + ? + + - ? 2 ( ) t 0 i i t j t j t i - - i=1 j=1 Avec la convention ai = 0 si i> q et /3j = 0 sij > p. Remarque : Le degré de p apparaît comme un degré de moyenne mobile de la représentation ARMA dans 2 et . A partir de cette représentation, on peut calculer de façon aussi simple les moments et les moments conditionnels du processus d'erreur { e t , t E cents } mais aussi du processus{X t ,tE cents }. Exemple : Considérons le cas d'un processus GARCH (1, 1) : ? ? = e i t t t h = + + > ~ ? a a 0 1 0 0 et 2 ? ? h h t t t a a e ? /3 ? 0 1 1 1 1 Qui peut être représenté par le modèle suivant : e a a /3 e u t /3 u t 2 = + + ? + -- ? ( ) 1 2 t 0 1 1 t 1 1 Où ( ) u t = e t ? Var e t / ? t ? 1 = e t ? h t 2 2 est un processus d'innovation pour 2 et . Sous la condition de stationnarité du second ordre a1 + /3 1< 1, la variance non conditionnelle du processus { X t , t E cents } est définie et constante dans le temps. Sachant que ( ) ( 2 ) Var e t = E e t il suffit, à partir de la forme ARMA (1, 1) sur 2 et de définir l'espérance du processus : Var < 1 ( ) ( 2 ) 0 a e e t E t avec = = + a /3 1-- - a /3 1 1 1 1 En fin, on peut montrer que, pour un processus GARCH, rappelons la Kurtosis est directement liée à l'hétèroscedasticité conditionnelle. Le cas de la Kurtosis associée à la loi non conditionnelle dans un processus GARCH conditionnellement gaussien : e t = i t h t Où i t ??? N iid (0, 1)
Dans ce cas, les moments conditionnels d'ordres 2 et 4 du processus { e t , t cents } sont liés : E e t I t _ 3 E e t I t 1 ( ) ( ) 2 4 = ? ? ? ? 2 1 _ En effet on rappelle que si une variable X suit une loi gaussienne centrée: E X = 3 Var X = 3 ? ? E X ? ? ( ) ( ) ( ) 2 4 2 2 Si l'on considère l'espérance des membres de cette équation, il vient : I t ? 1 E e t ) ( ) ? 4 ? = E E e t 4 ? ( ? 2 2 E E e I ? E E e t I t E e t ? ? ~ ? ? = ? ? ? ? ? ? ? ? ( ) ( ) ( ) 2 2 2 t t 3 1 3 1 ? Ainsi on déduit que la loi marginale a des queues plus épaisses qu'une loi normale puisque : E e t ~ 3 ? ? E e t ? ? ( ) ( ) 2 4 2 De plus, on peut calculer la Kurtosis comme suit : E ( ) e 4 Kurtosis= t 2 E ( ) e 2 t 2 3 E E I ? ? ( ) 2 ? ? e / t t _ 1 2 E ( ) e 2 t 2 E ( ) e 2 ( ) ( ) { ( ) ( ) } t 3 2 2 2 2 3 + ? ? / _ 2 2 2 2 ? ? e e e E E t t t E E e e t t = + ? ? r ? ( ) { ( ) ( ) ? 3 2 3 / / 2 2 2 E E E 2 1 ? ? ? ? ? ? e e e e t t t t _ ( ) e e 2 / ? t t _ 1 ?
e 2 E t Var E ? ? = + 3 3 E La Kurtosis est donc liée à une mesure de l'hétèroscedasticité conditionnelle. Proposition Si le processus{ e t , t E cents } satisfait une représentation GARCH (p, q) conditionnellement gaussienne, telle que : où ii Var ( ) 2 ( )t t / = = + ? + - e _ ? ?e ? _ I h h t t t i t i j 1 0 _ t j i j = = 1 1 ?? q p est un bruit blanc eii t t t = h
La loi marginale de{ e t , t E cents } a des queues plus épaisses qu'une loi normale (distribution leptokurtique). E e t ~ 3 ? ? E e t ? ? ( ) ( ) 2 4 2 Son coefficient d'excès de Kurtosis peut s'exprimer sous la forme suivante : E Kurtosis= 3 _ 2 E ( ) e 2 t ( ) e 4 t Var E ? ? ( ) 2 ? ? e e / = 3 t t _ 1 2 E ( ) e 2 II. Estimation, Prévision [Christian GOURIEROUX] Les paramètres du modèle GARCH peuvent être estimés selon différentes méthodes : Maximum de vraisemblance, pseudo maximum de vraisemblance, méthode des moments,... (Pour plus de détail voir Gourieroux 1997). Les méthodes généralement utilisées sont celles du maximum de vraisemblance (MV) ou pseudo maximum de vraisemblance (PMV). L'avantage de PMV réside dans le fait que l'estimateur obtenu converge malgré une mauvaise spécification (supposé normale) de la distribution conditionnelle des résidus à condition que sa loi spécifiée appartienne à la famille des lois exponentielles (Gourieroux et Mont fort 1 989).Ainsi l'estimateur de MV obtenu sous l'hypothèse de normalité des résidus et l'estimateur du PMV sont identiques. Seules leurs lois asymptotiques respectives différent. Toutefois dans le deux cas (MV ou PMV) sous l'hypothèse standard, l'estimateur est asymptotiquement convergent et asymptotiquement normal. II.1 Estimation II.1.1 Estimation par le pseudo maximum de vraisemblance (PMV) Soit {& t ,tE cents } un processus généré par un modèle GARCH (p, q) c'est-à-dire qu'il est solution des équations stochastiques suivantes : ? ? ?
& ij t t t = h 2 t ( ) ? ??? iid p q N 0, 1 (* *) ?? = ? ? ? ? j i = = 1 1 h h t j t j i t i a a ? ? ? ? 0 Où a0>0, ai~0 J3 j ~0 Vi=1,...,p, Vj=1,...,q Comme le montre l'équation (**), le processus { g t , t E cents } que nous avons défini a toutes ses observations conditionnellement au passé, et nous avons les densités conditionnelles alors nous exprimons la fonction de ses densités conditionnelles. Soit L(O / ? t ) la fonction du pseudo maximum de vraisemblance et O = a 0 , a 1 , . . . , a p , ? 1 , . .., o q le vecteur des paramètres inconnus. Nous notons f la fonction ( )' densité et ( )' ? t = ? 1,..., ? T où T est un entier positif. T
t = 1 T 2
? ( ? 1 L ( / ) 2 exp O ? ? = l _ ? 2 t ? ( ) t 2 h t 1 ? ? = t Nous obtenons la fonction log de vraisemblance suivante : ? T 2 - 1? ? ? ? log ( / ) log 2 exp 2 t ( ) ( ) L h 0 c ? = - t f f ? ? t ? ? ? 2 h ? t = 1 t ? T ? 2
- ? ? ? 1? f ? log 2 h log exp 2 t = f + - ( ) 7r ? t 2 h ? t 1 ? ? ? = t ? T ? ? t 1 ? ? = t ( ) h = f - ? log 2 r 2 t ? t 2 h 2 - ? 1
T ? ? 2 = - f + ? t 1 log 2 C ? ( ) ? h t 2 h t 1 ? ? = t 2 T Posons ( ) 1 l = - f t t 2 l o g 2 ? ? 1 r h e t + = t ? ? h T ? ? l t 1 l t t = C'est-à-dire ( ) 1 l h = f - log 2 ?T ? ir t ? 2 ? + ? ht t ? 2 T t = 1 ? La dérivée première et seconde de la fonction de vraisemblance : 5 l 1 1 1 T T ? 2 5 h h 5 = - 5 ? ? t t t + 0 0 0 2 2 2 T h T h t t t t = = 1 1 5 5 T 5 f ? - ? ? 2 1 1 h t t & ? 1 2 T h h t t t 0 = 1 5 ? ? Prenons par exemple le cas d'un GARCH (1, 1) c'est-à-dire ( )' 0 = a 0 , a 1 , /3 1 Donc la variance inconditionnelle est de la forme 2 h t = a 0 + a 1 ? t - 1 + /3 1 h t - 1 Qu'on peut écrire de la manière h h = + + a a ? /3 2 t t t 0 1 1 1 1 - - = 2 ( ) 2 h a ? /3 a a ? /3 a ++ + + 0 1 1 1 0 1 2 1 2 t - t t - - ( ) ( ) ( ) 2 2 2 2 = a /3 a e /3 e /3 a a g /3 h 1 + + + + + + 0 1 1 1 1 2 1 0 1 3 1 3 t t - - t t - - .
j j t 2 1 - a /3 a /3 E /3 = 0 1 1 1 1 1 1 + + h t j - - j j = = 0 0 Alors: 5 5 h h t - 2 t j t - 1 1 _. + ? /3 /3 1 1 5 5 a a 0 0 j = 1 t - 2 5 h 2 1 1 5 h t j t - = +
? /3 e /3 1 1 1 t - 5 a a 5 1 0 j = 1 5 h t t - 2 t - 2 1 j 1 2 t = + + - j 2 a /3 a /3 e /3 - - - 0 1 1 1 1 1 1 j j t h ( ) 1 t - j = 0 j = 0 Donc: 5 - - 5 1 1 1 T h l T 2 e t t 5 h ? L_i 5 t + a a a 2 0 1 2 2 T h T h t 1 t t 5 5 ? 0 ? t 0 = T 5 ? ( - ' ? 2 1 1 h t t e ? 1 2 T h h t t t 1 0 5 ? ? a ? ' ? ? T t 2 2 1 1 ( - e 1 1 5 ' ( h ? ? + - - j t t ? ? /3 /3 1 1 1 ? ? 2 2 T h t t j 1 0 ? 5 ? a h ? ? 1 ? t l h h 2 1 1 1 T 5 T 5 e 5 t T 5 ? ( - ' ?
2 1 1 h t t e ? 1 2 T h h t t t 1 1 5 ? ? a ? T t 2 2 1 1 ( - 2 1 1 5 ' ( ' h e j t ? + - - = ? ? t /3 e /3 1 1 1 ? ? ? 1 t - 2 T h t t j 1 0 ? 5 ? ? a h ? ? 1 ? t T 2 5 5 5 l T h h 1 1 1 e ? - + ? ? t t t 2 5 5 5 /3 /3 /3 2 2 T h T h t ? 1 t ? 1 1 t 1 t 1 2 1 1 T 5 h ( ' e
t t ? ? ? 2 T h ? - 1 t t t 1 1 5 /3 h ? ? 2 ' ( ' et II ? -1 ) ? h t - - 2 2 1 1 T t t ( j j t h j j 1 1 2 2 t - = ? ? ? - - ? a /3 a /3 e /3 + + - ? ? 1 0 1 1 1 1 1 1 t - 2Th t j j ? ? = 1 0 0 t ? La dérivée seconde est de la forme 5 5 5 5 ( 5 ' 5 ( 5 ' 5 5 ? 2 2 2 T ? 1 ? h h h h h h T l 1 1 1 e e - 2h t ' ' ' = ? + ? + ? ? ? t t t t t t t t ? ? ? ? ? 5 5 ? 5 5 5 ? 5 ) ] ? 5 ? 5 ) 5 5 6 6 ? 6 6 6 6 6 6 6 6 ' 2 4 ' 2 T h h h 2 t 1 t t ? 1 t t ] II.2 Prévision II.2.1 Forme des intervalles de prévision Considérons un modèle ARMA avec erreurs GARCH conditionnellement gaussiennes : ? ? ? ? ? ?IL q O e ( ) ( ) B X B t t =
? ? =h où . ? ? ? est un bruit blanc t t t t t q p t j - h h = ? ? 2 t 0 i t i j ? ? a a ? ? ? i 1 j 1 = = avec a0 > 0,a i ~ 0,/i j ~ 0 Vi=1p, j=1,q Un tel modèle peut être analysé de deux façons différentes :
?, O désignent les estimateurs des polynômes autorégressifs et moyenne mobile, les prévisions à horizon l des Xt , données par : $ ? ? ? X X = ? - ( ) 1 L , sont asymptotiquement sans biais. Les intervalles de prévision sont t ? ? ? ? ? ( ) u t L maintenant calculés par : [ X t #177; 2 h t ] u $ Ou ht u est l'estimation de la volatilité de la date t. la largeur de ces intervalles dépend maintenant de la date t considérée. III. Extensions des modèles ARCH / GARCH linéaires et non linéaires La méthodologie ARCH contribue à relâcher l'hypothèse forte de la constance de la volatilité dans le temps. Suite à l'article pionnier d'Engle, plusieurs variantes du modèle ARCH (p) ont été proposées afin de donner une meilleure description et prévision de la volatilité. Les chercheurs exploitent principalement deux dimensions pour améliorer les modèles GARCH. D'abord, ils s'intéressent aux autres distributions que la loi Normale pour les innovations. Aussi, ils recherchent des modèles plus flexibles expliquant mieux l'évolution de la volatilité. En règle générale, la classe des modèles ARCH peut être divisée en deux sous ensembles : les modèles ARCH linéaires et les modèles ARCH non linéaires. Les premiers regroupent les processus ARCH (p) et GARCH (p, q) décrits précédemment. D'autres variantes comme le modèle GARCH intégré (IGARCH) de Engle et Bollerslev (1986) et le modèle GARCH in Mean (GARCH-M) de Engle, Lilien et Robins (1987) s'ajoutent à la liste des modèles linéaires. Ensuite, la réaction de la volatilité à un choc sur le rendement peut être différente selon le signe du choc. Une mauvaise nouvelle a généralement un impact plus grand sur la volatilité qu'une bonne nouvelle dans le marché boursier. Ce mécanisme d'asymétrie sur la variance conditionnelle est modélisable par des processus ARCH non linéaires. L'omission de ce fait stylisée du marché, s'il est présent de manière significative, affectera potentiellement la spécification de la variance conditionnelle. L'estimation des extensions du modèles ARCH/GARCH est faite par la méthode de maximum de vraisemblance décrite précédemment et ce en supposant une distribution des rendements. III.1 Modèle IGARCH En bref, le processus IGARCH permet une persistance infinie de la volatilité. L'effet d'un choc se répercute sur les prévisions de toutes les valeurs futures. Sa spécification est identique à un modèle GARCH (p, q) à la différence qu'une contrainte sur la somme des coefficients est imposée, elle doit être égale à 1. Ceci implique que la variance non conditionnelle n'existe pas dans ce processus. Le modèle RiskMetrics ou moyenne mobile à pondération exponentielle (EWMA), développé par la banque d'investissement JP Morgan pour le calcul de la valeur à risque, est à la base un processus IGARCH (1,1) sans constante dans lequel pour les données quotidiennes, le coefficient suggéré pour le terme d'erreur au carré de la période précédente est 0.06 et celui de la variance conditionnelle retardée est 0.94.
Considéronsc t = ij t ht , le processus IGARCH s'écrit : p q h a a c ? J3 h ? = + ? + 2 t i t i j t j 0 i j = = 1 1 p q
variante du modèle IGARCH (1,1) : h t = 0.6c t ? 1 + 0.94 h t ? 1 2 Une extension plus fonctionnelle, le modèle GARCH fractionnellement intégré (FIGARCH), est proposée par Baillie, Bollerlsev et Mikkelsen (1996). Ce processus est un cas intermédiaire entre les modèles GARCH et IGARCH. La mémoire longue de la volatilité est prise en compte mais l'effet d'un choc n'est pas infini comme dans le modèle IGARCH, il décroît à un rythme hyperbolique. III.2 Modèle GARCH-M Quant au modèle GARCH-M, il introduit la volatilité comme un déterminant de la rentabilité. La variance conditionnelle est alors une variable explicative dans l'équation du rendement, elle intervient dans la fonction de régression pour conditionner le rendement espéré. L'équation de la variance conditionnelle du modèle GARCH-M est identique à la formulation standard du processus GARCH, elle peut être substituée par un autre processus de volatilité. Par exemple, un modèle asymétrique GARCH exponentiel (Nelson, 1991). La représentation GARCH-M est souvent utilisée pour étudier l'influence de la volatilité sur le rendement conditionnel des titres dans les travaux empiriques. La formulation GARCH-M s'écrit : Xt = HJ3 + 8ht + c t avec c t / I t ? 1 : N(0, ht)
Considérons e t = i t ht p q ha a e ? f3 h ? = ? ? + ? 2 t i t i j t j 0 i j = = 1 1 Dans l'ensemble, les modèles linéaires reposent sur une spécification quadratique des perturbations sur la variance conditionnelle. Ils supposent que c'est l'ampleur et non pas le signe des chocs qui détermine la volatilité. Par conséquent, les chocs positifs et négatifs de même taille ont un impact identique sur la variance conditionnelle. En d'autres termes, ce sont des processus symétriques. Pourtant, l'hypothèse d'effet asymétrique des chocs sur la volatilité, à savoir la variance conditionnelle réagit différemment aux chocs de même amplitude selon le signe de ces derniers, est très réaliste pour des séries financières et monétaires. Les modèles ARCH symétriques ont le désavantage de ne pas tenir compte de ce fait stylisé possible dans les séries étudiées. III.3 Modèle EGARCH Suite à la formulation GARCH de Bollerlev (1986), une seconde mise au point importante de la famille ARCH est sur la spécification de l'asymétrie de la volatilité introduite par Nelson (1991) lors d'une étude sur les rentabilités des titres boursiers américains. À première vue, le modèle EGARCH est caractérisé par une spécification asymétrique des perturbations. Il permet à de bonnes nouvelles et de mauvaises nouvelles d'avoir un impact différent sur la volatilité. L'évolution de la variance conditionnelle est expliquée par l'importance des termes d'erreur passés, le signe de ces erreurs et les variances conditionnelles retardées. Puis, Nelson considère que les conditions sur les paramètres du modèle GARCH sont contraignantes. Elles restreignent la dynamique réelle de la volatilité et la non-négativité des coefficients est souvent violée en pratique quand l'ordre d'un processus GARCH de paramètres p et q est grand. C'est pourquoi dans le modèle EGARCH, la variance conditionnelle est mise sous forme logarithmique donc elle demeure toujours positive. Dès lors, il n'est plus nécessaire d'imposer des restrictions de positivité sur des paramètres. Considérons : . et= it ht
L'équation de la variance conditionnelle d'un processus EGARCH (1,1) s'écrit : ln(h t ) a0 +a1 ? j ? ) ? + J 1 ln( a t - 1 ) + yj t - 1 ? 2 =
t - 1 - E( j t - 1 Où jt - 1 représente les résidus standardisés à la date t - 1. Le coefficient a1 mesure l'effet d'amplitude du terme d'erreur passé. Ensuite, le coefficient y capte l'effet du signe de l'erreur. La relation de récurrence entre la variance conditionnelle à celle de la période précédente est mesurée par le coefficient J1 . La valeur E(j t - 1 ) dépend de la loi supposée des innovations standardisées : Pour la distribution Normale :
E ( j t ) - 1 2 = ? Pour la loi de Student-t : 2 ( ?
v Fi i - v ? ) ? ? v E (j t - ) 2 1 = 2
? ( 1) v - F? ? Pour la loi Generalized Error Distribution (GED) :
E ( j t - 1 ) 2 ? ? ? ? F ? ? F ? ? ? ? ? ? v v Où F(.) désigne la fonction Gamma ? ? v F? ? ? ? Engle et Ng (1993) notent que la variabilité de la variance conditionnelle du modèle EGARCH est élevée, autrement dit la variance conditionnelle augmente très vite lorsque l'ampleur des perturbations est grande. Ceci peut conduire à des réactions exagérées de la variance conditionnelle dans la prévision. III.4 Modèle GJR-GARCH Une autre approche permettant de capter l'effet d'asymétrie des perturbations sur la variance conditionnelle est introduite par Glosten, Jagannathan et Runkle (1993). La formulation GJR-GARCH est en fait un modèle GARCH avec l'ajout d'une variable muette qui est multipliée par le carré du terme d'erreur de la période passée dans l'équation de la variance conditionnelle. C'est un modèle à seuil où la fonction indicatrice, c'est-à-dire la variable muette, est égale à 1 si le résidu de la période précédente est négatif et elle est nulle autrement. De cette façon, la variance conditionnelle suit deux processus différents selon le signe des termes d'erreur. Considérons c t = i t ht. L'équation de la variance conditionnelle d'un processus GJR-GARCH s'écrit : p q h a a c ? J3 h ? yc ? L ? = + + + 2 2 t i t i j t j t t 0 1 1 i j = = 1 1 Où L t ? 1 =1 si c t ? 1 <0, 0 sinon p q
L'étude de Glosten, Jagannathan et Runkle (1993) porte également sur le lien entre la prime de risque et la variance conditionnelle des rendements boursiers aux États-Unis. Différentes spécifications du modèle GARCH-M sont utilisées pour fins d'analyse, notamment le modèle GJR-GARCH (p, q) qui capte l'effet d'asymétrie des perturbations sur la variance conditionnelle. Les auteurs se servent des données mensuelles plutôt que journalière de l'indice de la valeur pondéré par la capitalisation boursière de CRSP (Center Research Security Prises) pour réaliser l'étude. La période concernée allant d'avril 1951 à décembre 1989. À la lumière des résultats, les chocs négatifs provoquent une augmentation de la variance conditionnelle plus forte que des chocs positifs. De plus, au sujet de l'impact de la variance conditionnelle sur l'espérance conditionnelle du taux de rendement excédentaire, le coefficient estimé est négatif comme dans l'article de Nelson (1991) et en plus il est statistiquement différent de zéro. Une hausse de la variance conditionnelle est donc associée à un décroissement du rendement conditionnel. Pourtant, ce résultat est en contradiction avec la plupart des modèles d'évaluation d'actifs qui postulent qu'un actif risqué devrait offrir un rendement supérieur à un actif moins risqué. Dans la littérature financière, cette relation négative entre les rendements conditionnels et la variance conditionnelle est appuyée par plusieurs travaux, notamment ceux de Black (1976), Bekaert et Wu (2000), de Whitelaw (2000) et de Li et al. (2005). Ce phénomène peut être expliqué par l'effet de levier financier initialement discuté dans l'article de Black (1976), à savoir une baisse du prix d'un titre (rendement négatif) augmente le ratio emprunts/capitaux propres de l'entreprise en question. Sachant qu'une entreprise plus endettée est plus risquée, donc la volatilité du titre augmente. Une autre explication possible du phénomène est le concept de volatility feedback (Pindyck, 1984 ; French et al. 1987) qui suggère qu'une hausse anticipée de la volatilité accroisse le rendement exigé par les investisseurs puisque le titre deviendra plus risqué, ceci implique que la valeur du titre diminue immédiatement toutes choses étant égales par ailleurs.
III.5 Modèle TGARCH Considérons c t =? tht l'équation de la variance conditionnelle d'un processus TGARCH s'écrit :
p q h t i t i j t j t t = + ? + + a a c ? J3 h ? yc ? L ? 0 1 1 1 1 j = i= Où L t ? 1 =1 si c t ? 1 <0, 0 sinon Le modèle TGARCH (Threshold GARCH) de Zakoian (1994) est similaire au processus GJRGARCH à la différence qu'il spécifie l'asymétrie sur l'écart-type conditionnel et non sur la variance conditionnelle. Il s'agit d'un modèle à seuil où la dynamique de l'écart-type conditionnel des rendements diffère selon le signe des termes d'erreur. L'équation de l'écart-type conditionnel de TGARCH (1,1) est une fonction linéaire par morceau selon le signe du choc et l'écart-type conditionnel de la période précédente. Par ailleurs, dans le modèle TGARCH, il est possible d'observer une discontinuité de la dérivée de la variance conditionnelle par rapport aux perturbations au voisinage de zéro de telle sorte que les problèmes d'estimation sont plus complexes que le modèle GJR-GARCH. Une extension du modèle est suggérée dans l'article de Rabemananjara et Zakoian (1993), les auteurs exposent qu'il est possible de relâcher les conditions de positivité sur des paramètres, autorisant ainsi un comportement oscillatoire de l'écart-type conditionnel (en valeur absolue) par rapport à la valeur du choc de la période passée. Nous avons présenté les 3 modèles asymétriques classiques dans la littérature financière. D'autres travaux sur les modèles non linéaires existent, comme ceux concernant les modèles NARCH (Nonlinear ARCH) de Higgins and Bera (1992), NAGARCH (Nonlinear Asymmetric GARCH) de Engel et Ng (1993) et APARCH (Asymmetric Power ARCH) de Ding, Engle et Granger (1993). Pour une description détaillée de la littérature référant aux autres modèles non linéaires, nous renvoyons aux travaux de Hentschel (1995). L'auteur regroupe les modèles asymétriques dans une forme générale. Il compare notamment les modèles par les courbes de réponse à des perturbations (news impact curves). Il s'agit d'une méthode de comparaison proposée par Engel et Ng (1993), représentant des effets des perturbations sur la variance conditionnelle. Par exemple, la courbe de l'impact des chocs associés au processus GARCH standard est symétrique et elle est centrée à l'origine. Ceci justifie que le modèle accorde une même importance aux innovations négatives que positives de force égale sur la volatilité. Pour les modèles EGARCH, GJR-GARCH et TGARCH, leur courbe de réponse à des nouvelles est centrée à l'origine mais asymétrique, ce qui signifie que la variance conditionnelle répond de manière différente au choc de même amplitude selon le signe de ce dernier. Quant au modèle NAGARCH, il se distingue par le fait que sa courbe de l'impact des perturbations est asymétrique et de plus elle n'est pas nécessairement centrée à l'origine. IV Séries de rendements En général il très intéressant de voir juste le prix d'un investissement à savoir un titre financier dans notre cas. Du point de vue d'un investisseur le rendement de l'investissement est beaucoup plus intéressant. Principalement du fait qu'un investisseur insiste plus sur le gain relatif réalisable, plutôt que sur le prix nominal de l'investissement, mais aussi parce que le rendement comme indice de changement du prix relatif permet de capitaliser entre compagnies, titres bousiers et monnaies. En plus du fait que les rendements sont généralement stationnaires, une propriété que ne possède pas le prix actuel des titres. Dans le monde de la finance le concept de rendement n'est pas défini de manière claire. Soit Xt le prix d'un titre au temps t le rendement à l'instant t peut être défini par : Définition 1 : (le taux de rendement arithmétique) :
= t t
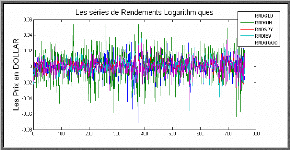
X = I ? X t log L ? t _ 1 Les deux rendements sont reliés par la formule suivante du moins pour les rendements quotidiens : r e r r t 1, 2, t = 2, -- 1 ; t Le taux de rendement géométrique est aussi dit rendement composé. Tout au long de cette partie on utilise le taux de rendement géométrique car il est le plus utilisé dans diverses recherches ce qui permet de comparer les résultats obtenus. IV.1 Propriétés statistiques des séries de rendement Les séries des prix d'actifs et de rendements présentent généralement un certain nombre de propriétés similaires suivant leurs périodicités. Soit Xt , le prix d'un actif à la date t et rt le logarithme du rendement correspondant : r t = X t - X t ? log log 1
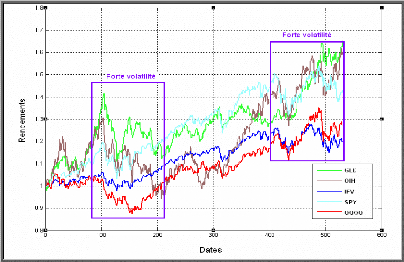
Charpentier (2002) distingue six principales propriétés qu'on va aborder successivement. Propriété 1 (stationnarité) Les processus stochastiques ( t ) t X associés aux prix d'actifs sont généralement non stationnaire au sens de la stationnarité du second ordre, tandis que les processus associés aux rendements sont compatibles avec la propriété de stationnarité au second ordre. Propriété 2 Les autocorrélations des variations de prix. La série 2 rt associées au carrées de rendement présente généralement des fortes autocorrélations, tandis que les autocorrélations de la série rt sont souvent très faibles (hypothèse du bruit blanc). Propriété 3 (queues de distribution épaisse) L'hypothèse de normalité de rendements est généralement rejetée. Les queues des distributions empiriques des rendements sont généralement plus épaisses que celle d'une loi gaussienne. On parle alors de distribution leptokurtique. Propriété 4 (clusters de volatilité) On observe empiriquement que de fortes variations des rendements sont généralement suivies de fortes variations. On assiste ainsi à un regroupement des extrêmes des clusters ou paquets de volatilités. Propriété 5 (queues épaisses conditionnelles) Même une fois corrigée, la volatilité de clustering (comme pour le modèle ARCH) la distribution des résidus demeure leptokurtique même si la kurtosis est plus faible que dans le cas non conditionnel. Propriété 6 (effet de levier) Il existe une asymétrie entre l'effet des valeurs passées négatives et l'effet des valeurs passées positives sur la volatilité des cours ou des rendements. Les baisses de cours tendent à engendrer une augmentation de la volatilité supérieure à celle induite par une hausse des cours de même ampleur. IV.2 Modèle des séries des rendements ? = + t t ? ? ? ? &ij t tt h
Les séries des rendements sont souvent modélisées par des modèles GARCH. Prenons pour exemple un modèle GARCH (1, 1), il s'écrit sous la forme suivante : ? ?L = + + h h a a ? ? fl ? 2 t 0 1 1 1 1 t t Avec a0 > 0, a1 ~ 0, /3 1 ~ 0 et C représente la moyenne de la série rt . Analyse et estimation des séries de rendements Dans cette partie on utilise le modèle par défaut GARCH toolbox (boite à outils), pour estimer les paramètres nécessaires à la modélisation des séries de rendements. ? = + r C t t ? ?
? = ? 17 h t t t ? ?L = + + a a ? fi ? 2 h h t 0 1 1 1 1 t t Avec a0 > 0, a 1 ~ 0, /3 1 ~ 0 et C représente la moyenne de la série rt . Les étapes à suivre sont les suivantes :
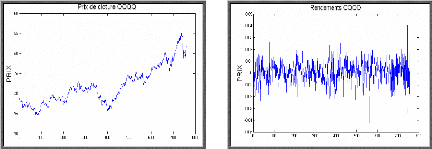
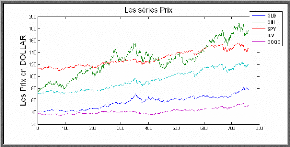
Série de rendement RNDQQQQ 1- Pre-estimation ? Graphe de la série brute QQQQ et la série de rendements RNDQQQQ
On voit clairement sur le graphe de la série brute QQQQ que ce processus est non stationnaire, et cela provient de l'inclusion de la tendance (caractéristique des séries de prix), par contre la série de rendements logarithmiques RNDQQQQ à droite semble stationnaire autour de sa moyenne, ce qui est une propriété principales des séries de rendements. Pour confirmer ou infirmer cette stationnarité on procède dans un premier temps à l'analyse des corrélogrammes simple et partiel. ? Corrélogramme simple et partielle de la série RNDQQQQ
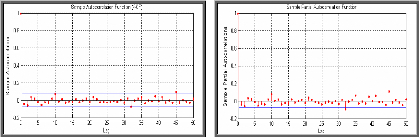
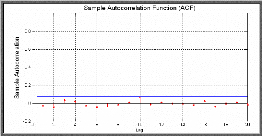
D'après les corrélogrammes simple et partiel, on remarque que presque tous les pics sont non significatifs, ce qui confirme la propriété de non corrélation des rendements. s Corrélogramme des rendements au carré RNDQQQQ
On remarque d'après le corrélogramme des rendements au carré que les autocorrélations sont nettement significatives, cela peut être expliqué par une forte corrélation et une persistance du moment de second ordre. Mesure de la corrélation On peut quantifier les autocorrélations précédentes en utilisant les tests d'hypothèses formelles, comme le test de Ljung Box-Pierce et le test ARCH d'Engel. Sous MATLAB la fonction lbqtest implémente le test de Ljung Box-Pierce Q-test qui suppose sous l'hypothèse nulle que les rendements sont aléatoires.
En utilisant le test de Box Ljung, on peut vérifier qu'il n'y a pas de corrélation significative entre les rendements. Remarque Dans les tableaux qui suivent, la sortie H est une décision booléenne, H=0 veut dire qu'il n'y a pas de corrélation significative, H=1 implique l'existence d'une corrélation significative.
D'après le test on remarque que H=0, les probabilités sont toutes supérieures à 5% et les T-Stat sont inférieures aux valeurs critiques, donc on accepte l'hypothèse de non corrélation des rendements. s Engel's ARCH Test Pour appliquer le test de Engel, on implémente la fonction ARCH test qui vérifie la présence d'un effet ARCH, sous l'hypothèse nulle la série de rendements est une séquence aléatoire gaussienne (c'est-à-dire pas d'effet ARCH)
D'après le test H=1, les P-value sont nulles et les T-Stat sont supérieures aux valeurs critiques, donc on rejette l'hypothèse nulle, c'est-à-dire qu'il existe un effet ARCH. 2- Estimation des paramètres La présence d'hétéroscédasticité vue dans l'analyse précédente, indique que la modélisation GARCH est appropriée pour mettre en oeuvre ce phénomène.
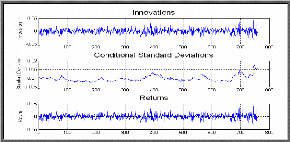
On remarque que tous les paramètres du modèle sont significativement différents de zéro. La condition de positivité des paramètres et aussi vérifiée. Donc le modèle GARCH(1, 1) peut s'écrire sous la forme suivante : ? = + -8 RNDQQQQ t 4.6524 e ? t ? h ( ) 0, 1 ? ??? Où N iid ? 7 ri t t t = t ? ?L = + + 2.3721 10 0.04946 0.92729 -6 2 h g t t t -1 -1 h 3- Post-estimation On utilise le graphique ci-dessous pour inspecter le rapport entre les innovations (résidus) dérivées du modèle estimé, les écarts types conditionnels et les rendements observés.
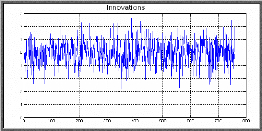
- Comparaison des innovations, écarts types conditionnels et rendements- On remarque dans la figure précédente que les innovations et les rendements montrent des faibles clusters de volatilité, on note aussi que la somme a1 + ? 1 = 0.04946+0.92729 est égale à 0,97675 (strictement inférieurs à 1) ; donc la condition de stationnarité du processus GARCH est vérifiée. ? Graphe des innovations standardisées
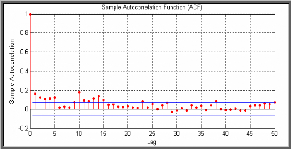
D'après le graphe des résidus standardisés, on voit clairement qu'ils montrent une stabilité au cours du temps, avec peu de clusters. s Corrélogramme des résidus standardisés au carré
D'après le corrélogramme, on voit clairement l'absence de corrélations des résidus standardisés élevés au carré, car aucun pic n'est significatif. Pour confirmer cela, on effectue le test de Box Ljung-Pierce Q-Test et le test d'Engle. ? Ljung Box-Pierce Q-Test
D'après le test on remarque que H=0, les probabilités sont toutes supérieures à 5% et les TStat sont inférieures aux valeurs critiques, donc on accepte l'hypothèse de non corrélation des résidus standardisés. s Engel's ARCH Test
D'après le test H=0, les P-value sont supérieures à 5% et les T-Stat sont inférieures aux valeurs critiques, donc on accepte l'hypothèse nulle, c'est-à-dire qu'il n'existe pas d'effet ARCH sur les résidus standardisés. Conclusion L'étape de post-estimation sur les résidus standardisés montre la puissance explicative et confirme l'adéquation du modèle par défaut. Pour les autres séries RNDGLD, RNDSPY et RNDIEV, on a appliqué la même procédure, on a obtenu les modèles suivants : Série de rendement RNDGLD
Donc le modèle GARCH (1, 1) peut s'écrire sous la forme suivante :
iid t t t = ? h i Où N ??? t -6 2 h = + + 9.46 16 10 0.052564 0.94348 E t t t -1 -1 h ? ? ? ? ?
( ) 0, 1 E Série de rendement RNDSPY
Donc le modèle GARCH (1, 1) peut s'écrire sous la forme suivante : h = 5.911310 t -6 2 + + 0.065529 0.90204 E t t -1 -1 h ? ? RNDSPY 0.00046062 E t = + t iid E ii t t t = h ? Où N t ???
( ) 0, 1 ? ??? iid E ? t t t = h Où N t ? ?
( ) 0, 1 Série de rendement RNDIEV
Donc le modèle GARCH (1, 1) peut s'écrire sous la forme suivante : ? i ??) iid ? t t t = h OùN t h = 6.2741 10 t ? ? ? ? ?
-6 2 + + 0.031218 0.95158 c t t -1 -1 h ( ) 0, 1 RND OIH t t 0.0013296 ? & + Série de rendement RNDOIH
Donc le modèle GARCH (1, 1) peut s'écrire sous la forme suivante :
Une première approche est l'extension directe du modèle ARCH au cas multivarié. Elle a été introduite en premier par Engle, Granger et Kraft (1984). Il s'agit d'un modèle ARCH dans lequel chaque variance conditionnelle dépend non seulement de ses propres erreurs au carré des périodes précédentes, mais aussi de celles de l'autre variable du système ainsi que du produit croisé des erreurs passées des deux variables. En appliquant une même extension sur le processus GARCH (1,1), nous obtenons la forme générale du modèle VEC (1,1) proposée par Bollerslev, Engle et Wooldridge (1988). Cette méthodologie permet une dépendance dynamique entre les séries étudiées. Le modèle VEC (1, 1) est défini par : 1 h = C + Ai7 + Gh t ? t t Où C est un vecteur et A, G sont des matrices h t = Vech(H t ) i7 t = Vech(s t s t ) ' Le terme Vech est un opérateur matriciel qui stocke les
éléments de la partie triangulaire (N (N+1)/2 x 1). Prenons un portefeuille à 3 actifs. ? h h h 11 12 13 t t t H h h h ? t t t t = ? 21 22 23 ? ? h h h (h 11 t , h21 t , h31 t , h22 t , h32 t , h33 t ) ' 31 32 33 t t t Alors Vech(H t ) = L'opérateur Vec sert à empiler tous les éléments de la matrice Ht dans un vecteur colonne de dimension ((N x N) X 1). Par exemple pour N=3 On a Vec(H t) -- (h, . ,.1t , h21t , h31t , h12t , h22t, h32t , h13t , h23t , h33t ) Propriété de l'opérateur Vech Vec(ABC)-- (C' 0 A)VecB (II.1) Où ® est le produit de Kronecker ? ? ? IL [ 1[ h1 h h (II.2) (II.3) 2 1 1 t = C 1 1 + a 11' 1t-1 + g 11h11t -1 (II.4) 2 2 t = 2 C 2 2 #177; a 3 3£ 2 t -1 + g 3 3 h 2 2 t -1 Prenons par exemple un modèle Vech (1, 1) :
h22tC22 hÿÿ11t [C11 h21t = C12 + a21 a22 a23 '1t-1'2t-1 + g21 g22 g23 k a11 a12 a13 1 '12t-1 1 g11 g12 g13 1 k1t-1 1
'2a31a32a33j2t - 1jg31g32g33j h 22t - 1j 02 _, , '2 _, 1t - 1 L'écriture équivalente donne : 1t = C11 #177; a11-1t-1 ' -12'1t-1-2t-1 #177; a132t-1 ' g11h21t-1 + g12h22t-1 + g13h22t-1 2 21t = C12 + a21' 1t + , -i . `^ 2 2t 22t = C22 +a31'11-12_,, ir-i ' '^'32'1t-1' 2t4 #177; a33'2,t-1 ' _, g31h21t-1 #177; g32 h22t_1 #177; g33 h22t_1 [ Donc pour deux titres financiers le nombre des paramètres à estimer est de 21 dans un modèle VEC (1, 1). Cet exemple met en évidence l'inconvénient majeur du modèle VEC qui est le nombre de paramètres à estimer, il devient de plus en plus grand au fur et à mesure que le nombre des variables augmente. Ainsi, pour un modèle VEC(1, 1) avec 4 titres (actifs) à modéliser conjointement, le nombre de paramètres est égal à 210 et avec 8 titres il atteint 2628. Afm de réduire le nombre de paramètres à estimer, les auteurs suggèrent la formulation Diagonal VEC (DVEC). En supposant que les matrices A et G sont diagonales, le nombre des paramètres est égal à 9 pour un VEC (1, 1). Dans ce cas les équations deviennent : h h 21 t = C + a t-l'2t-1 + g 1 2 g 2 2h 2 1 t -1 h En supposant que certaines matrices sont diagonales, modéliser conjointement 8 actifs dans la formulation DVEC (1, 1) demande maintenant l'estimation de 52 paramètres. Les éléments du modèle DVEC (1, 1) suivent en fait un GARCH (1, 1), a savoir que chaque variance conditionnelle est déterminée par le carré de leurs propres erreurs précédentes et son propre retard tandis que la covariance de deux éléments dépend du produit croisé des erreurs passées des deux éléments impliqués et de son propre retard. Cependant, le grand désavantage de ce modèle est l'absence de l'interdépendance entre les composantes du système donc la transmission de chocs entre les variables n'est pas possible. Les variations de la volatilité d'une variable n'influencent pas le comportement des autres variables dans le système. D'autre part, la positivité de la matrice des variances-covariances conditionnelles n'est pas garantie par le modèle. Il faudrait imposer des restrictions sur chaque élément de la matrice des variances-covariances conditionnelles. Etant donné, la condition de positivité de la matrice Ht , nous pouvons réécrire le système sous forme matricielle de la façon suivante : f ? a12 ? ?f ? a 11 2 e 1 1 - 11 11 1 1 2 1 = + ? ?? ? t h C t t t ( ) e e - - ? ?\ ) a e 12 2 1 t - ? ? a 22 \ ? 2 a 22 f ? ? ?f ? a 21 2 e ? ?? ? ? ?\ ? a e 22 2 1 t - ? ? a 23 \ ? 2 1 1 h C 21 12 1 1 2 1 t t t = + ( ) e e - - (II.5) t - f ? a32 ? ?f ? a312 e ? ?[ ? 1 1 t - ? ? a 22 \ ? ? I\ ? a e h C 22 22 1 1 2 1 t t t = + ( ) e e - - 32 2 1 t - 2 Si nous écrivons les trois dernières équations sous formes matricielles, nous obtenons H t f a a a a e / 2 / 2 0 11 12 21 22 1 1 ?f ? t - 0 0 /2 /2 0 ?? ? C C = ? ? ?? ? ? ?? ? 11 12 1 1 2 1 12 13 22 23 2 1 e e a a a a e ? f ? f ? ? t t - - t - (II.6) 0 0 / 2 /2 0 ?? ? \ ) \ j C C 12 22 1 1 2 1 21 22 31 32 1 1 e e a a a a e t t - - t - ? /2 / 2 / 2 0 ?? ? \ a a a a e 22 23 32 33 2 1 ?\ ? t - Si nous notons A° la matrice de dimension 4 X4, alors la forme matricielle du modèle Vech (1, 1) peut être écrite comme : H t = C + I N ® e t - 1 A I N ® e t - 1 ( )°? ) ' Et la condition de positivité implique C ~ 0 et A ° ~ 0 avec au moins une inégalité stricte. III. Modèle BEKK Une approche qui garantit la positivité de la matrice des variances-covariances conditionnelles est suggérée initialement par Baba, Engle, Kraft et Kroner (1990). Puis, elle a été synthétisée dans l'article d'Engle et Kroner (1995). Le modèle BEKK (p, q, k) prend en compte des interactions entre les variables étudiées. L'équation suivante spécifie un modèle BEKK (1, 1, K) :
Où C , A k et G k * * * sont des matrices de dimension (Nx N) et C* est une matrice triangulaire supérieure et ' CC * * = . On observe que le 1er et le 2e terme de l'équation sont positifs et donc pour que Ht soit positive, il faut que Ht_1 soit positive. Voici un modèle BEKK (1, 1, 1). ' 2 h h C C C 1 = [ 1 [ 1 [ 1 [ 1 [ 1 [ ? ? * * * * * * * a a 11 21 11 11 21 11 12 1 1 1 1 2 1 0 a a 8 8 8 t t 11 12 ? ? ? ? + ? ? ? ? t t t _ _ _ ? ? ? 2 h h C C C * * * * * 21 22 21 22 22 21 22 1 1 2 1 2 1 0 a a 8 8 8 t t ? J [ ] a a * * J ? j ? j ? ] t t t _ _ _ 21 22
Nous observons que le nombre de paramètres à estimer est réduit à 11 avec un modèle BEKK (1, 1, 1) (21 pour le modèle Vech (1, 1). Si on utilise (II.1), nous pouvons écrire le modèle (6) comme un modèle VEC : Vec H A A Vec 8 8 G G Vec H t ( t ) ( ) ( ) ( ) ( 1 ) = ? + ® + 0 _ * * ' ' * * ' t t _ _ 1 1 D'ailleurs, le modèle BEKK est faiblement stationnaire si les racines caractéristiques De ( A A ) ( G G ) * * * * ® + ® sont plus petites que 1 en valeur absolue et donc nous avons : _ 1 Vec E VecH A A G G Vec ( ) ( ) ( 2 ( ) ( ) ) ( ) >. = = I _ ® _ ® Q t N ' ' * * * * Néanmoins, bien que le nombre des paramètres à estimer soit inférieur à celui du modèle Vech, il demeure encore très élevé. Par exemple, pour un modèle BEKK (1, 1, 8) ayant 8 actifs dans le système, il faut estimer jusqu'à 164 paramètres. Les recherches utilisant ce modèle limitent le nombre d'actifs étudiés et/ou imposent des restrictions comme de supposer que les corrélations sont constantes (Bollerslev 1990). Cependant, cette hypothèse est très forte puisque plusieurs travaux empiriques montrent que les corrélations varient au cours du temps. Le processus FARCH (Factor ARCH) proposé par Engle, Ng et Rothschild (1990) est un cas particulier du modèle BEKK avec des facteurs communs dans la volatilité des séries. En imposant une structure commune aux éléments de la matrice des variances-covariances, le nombre de paramètres à estimer dans un modèle FGARCH (1, 1, 8) est réduit à 54. IV. Modèle CCC Comparée aux modèles multivariés précédents, la formulation CCC (Constant Conditional Correlation) de Bollerslev (1990) diminue grandement le nombre de paramètres à estimer. Par exemple, modéliser conjointement 8 actifs exige l'estimation de 52 paramètres. D'ailleurs, le modèle permet aux covariances conditionnelles de varier dans le temps, mais en supposant que les corrélations entre les variables restent constantes. La méthodologie CCC consiste à estimer en premier la variance conditionnelle de chaque variable du système avec un modèle de type ARCH quelconque. Une matrice diagonale contenant ces variances conditionnelles est ensuite construite et la racine carrée de cette matrice donne une matrice diagonale des écart- types conditionnels Dt des variables étudiées. Le calcul de la matrice des variances covariances conditionnelles est obtenue par le produit de trois matrices : la matrice diagonale des écart-types conditionnels(Dt), la matrice de la structure des corrélations entre les variables (R) et la matrice diagonale des écart-types conditionnels(Dt). L HD RD t t t =
Ddiag h h h t t t NNt = ( 11 , 22 ,..., ) R p avec ? i n = ? ? ij ii , 1 1,..., Où R est un une matrice (N x N) contenant les corrélations constantes. Les variances conditionnelles hiit pour i= 1, ..., N, sont estimés à partir d'un modèle GARCH univarié. Nous pouvons écrire la covariance entre deux actifs hijt comme :
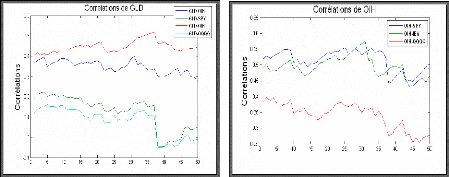
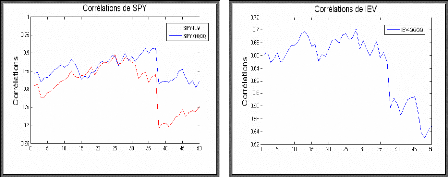
h ijt = p ij h iit h jjt , Vi ~ j La matrice des variances-covariances conditionnelles est presque toujours définie positive en pratique en raison de la méthodologie d'estimation. L'hypothèse fondamentale du modèle CCC est le fait que les corrélations conditionnelles sont constantes dans le temps. L'avantage de cette hypothèse est la facilité de l'estimation des paramètres et le nombre moins grand de paramètres à estimer. Mais, comme le modèle BEKK, l'hypothèse de constance des corrélations ne résiste pas à la réalité des faits. La condition de positivité de Ht exige la positivité de R et de hiit pour i=1,..., N. Dans le modèle CCC, les éléments de la matrice des corrélations R sont constants. La dynamique de la covariance est déterminée seulement par deux variances conditionnelles, ce qui implique un paramètres en R (matrice des corrélations). nombre de ( 1) N N - 2 Pour une description détaillée des modèles GARCH multivariés présentés précédemment, le nombre de paramètres à estimer représente un problème majeur dans l'application des modèles multivariés. Dans ces conditions, il faut faire des compromis notamment limiter le nombre d'actifs à modéliser dans le système et imposer des restrictions comme la constance des corrélations dans le temps. En effet, les modèles présentés précédemment permettent aux covariances conditionnelles entre les variables étudiées de changer dans le temps mais ces variations sont entièrement attribuées aux fluctuations des variances conditionnelles. Ainsi, Tse (2000), en utilisant le test du multiplicateur de Lagrange, rejettent l'hypothèse nulle de constance des corrélations entre les marchés boursiers de Hong Kong, Japon et Singapore estimées à partir d'un modèle GARCH multivarié BEKK de Engle et Kroner (1995). Par ailleurs, les mécanismes d'asymétrie des chocs sur les variances et les corrélations conditionnelles ne sont pas pris en considération par ces modèles (à l'exception du modèle CCC où il est possible de modéliser la variance conditionnelle des séries avec des modèles ARCH non linéaires). Cependant, il est établi que la volatilité peut réagir différemment selon le signe des chocs et la corrélation entres les marchés boursiers a tendance à augmenter en période de baisse. La négligence de ces phénomènes constitue une source d'erreur possible dans l'estimation de la matrice des variances-covariances conditionnelle, particulièrement dans les situations extrêmes comme une crise financière. Estimation de la matrice de corrélation Soit rt le vecteur de rendements et &t le vecteur de résidus standardisés 1 & t D t ? r t ? L'estimation de la matrice de corrélation constante est donnée par : R ' & & tt 1 T ? ?T
IV.1 Test de constance de corrélation Une motivation première de cette approche est que les corrélations entre les actifs ne soient pas constantes au cours du temps. Il faudra donc effectuer un test de constance de corrélation. Il s'agit d'un problème difficile. Engle et Sheppard (2001) ont proposé le test suivant : p H0 : Rt R,V te T Contre H1 : Vechu(Rt) VechuR)+EfiiVechu(Rt_i) i Où Vechu est un Vech modifié qui choisit seulement les éléments au dessus de la diagonale. Rt c'est la matrice de corrélation dynamique. Après avoir estimé les modèles GARCH univarié on standardise les résidus pour chaque série, soit Di1rt On estime ensuite la corrélation entre les résidus standardisés et on standardise conjointement 1
Où R2 est la racine carrée de la matrice symétrique R . Sous l'hypothèse nulle de corrélation constante, ces résidus sont indépendants identiquement distribués (iid) de matrice de variance covariance 1k . Var R 21 etj R 2 Var(et)R2 R2RR2 1k H0 H0
Si l'on considère Vechu R 2 e e 1 1 tt 2 on remarque que - - EH0 [VechuR 2etetR 2 VechuEH0 2etetR 2 Vechu (1k) (c)~ ~ ~ (c)~ ~ Soit le processus centré{ Yt, te `~ . En supposant une dynamique linéaire de la forme du processus suivant : Yt a1k + fi1Yt~~1+ ...+ fi sYt~~s + ri t,t s +1,..., T Où (rit )test processus centré i.i.d du second ordre de variance a2 . Engle et Sheppard proposent pour le test de : H0: "a 0, et fii 0; V i 1,p" Contre H1 :a # 0 3ie 1,s tq fii #0 Yt est de dimension k(k -1) 2 . Y1 a + fi1Ys+ ...+ fi sY1+ri1 Ys+2 a + fi1Ys+1+ ...+ fi)72 +ri s+2 . YT a + fiYT-1 L'écriture matricielle est de la forme suivante : 1Ys . . . Y1 1 . . . Y Y s + 1 2 . . . . . . . . . 1 . . . Y Y T - 1 T s - ? ? ? ? ? ? ? ? ? ? + = X ? ? ? ?
8 ij ? = X X X Y Avec ( $ ) 1 $ ( ) ' ' EH 0 ? = 0 s + et $ ( ) Var ? = X X a ' 2 Ceci est justifié asymptotiquement (Hamilton (1994) P.2 15) On estime 2 cr par : 1 T = ?T S t s = + s Y Y t k j t j - I - ? a J3 - j = 1 ? u 2 1 2 - La statistique de test est la suivante. Il s'agit du tester de Wald adapté à ce problème (Hamilton 1990)
degré de liberté. La règle de décision est la suivante :
Sinon H0 est acceptée. V. Modèle DCC (Dynamic Conditional Correlation) Une approche récente pour modéliser à la fois les variances et les corrélations conditionnelles de plusieurs séries est la méthode DCC (Dynamic Conditional Correlation) proposée par Engle (2002) et Tse et Tsui (2002). S'inspirant du modèle CCC, la démarche de l'estimation comporte 2 étapes. En premier, la variance conditionnelle de chaque variable du système est estimée à partir d'un processus de type ARCH ou GARCH univarié quelconque. A ce point, il est possible de choisir un modèle non linéaire pour prendre en compte le mécanisme asymétrique des chocs sur la volatilité si le phénomène est significativement présent dans la série. Par la suite, les résidus standardisés des régressions effectuées à la première étape sont utilisés pour modéliser les corrélations de façon autorégressive, obtenant ainsi la matrice des corrélations conditionnelles qui varie dans le temps. La matrice des variances-covariances conditionnelles est le produit de la matrice diagonale des écart-types conditionnels par la matrice des corrélations conditionnelles et par la matrice diagonale des écart-types conditionnels. Le modèle DCC proposé par Engle (2002) s'écrit de la manière suivante : ~°~®~ °~~ Ht DtRtDt D diag t ( h1 1t , h22,...,hNNt )
Où R t est la matrice de corrélation conditionnelle qui peut être obtenue par l'équation : Et-(CtC;) Di 1HtDt-1 Rt Car Ct Di 1r On modélise Rt de la manière suivante : Qt (1- a - /3 )Q + a (CtC;)#177; /3 Qt-1 -Rt (diagQt) 1/ 2 Qt (diag Qt )-1/2 Qt c'est la matrice de variances-covariances conditionnelles des résidus standardisées. Où Q est la matrice de variances-covariances inconditionnelle de dimension(Nx N), \' symétrique et définie positive alors que Et=(å1t,å2t ,...,åNt est un vecteur colonne des
résidus standardisés des N actifs du portefeuille à la date t, ri i t C t Où rit hitCit V i 1,2 avec{ Cit , te cents`~ iid, de (V. 1) on obtient : pour i=1,...,N h iit P12Et-1( kt h2t CuCu)Et-1 (C1tC2t h1th2
les coefficients a et /3 sont des paramètres à estimer. La somme de ces coefficients doit être inférieure à 1 pour respecter la positivité de la matrice Qt. Corrélation conditionnelle. Soient deux variables aléatoires r1t et r2t centrées
(rtr2t)E (r r ) 2t (V. 1) Car Et-1(rit) hit P Et-1 12,t 2 2 E1 fritgt-1(r2t) t- t h1th2 Alors on a : Ainsi on peut dire que la corrélation conditionnelle entre les variables est aussi la covariance entre les résidus standardisés. Rt( Q t ) Q t ( Q t ) où Q t * diag Q t * 1/ 2 * 1/ 2 - - = { } { } = V.1 Estimation des paramètres Pour estimer les paramètres ( )' ? = a 0 ,a1 , ...,a p ,ii 1 ,..., ii q nous devons passer par une estimation du maximum de vraisemblance logarithmique. En supposant que les résidus sont gaussiens centrés, la fonction de vraisemblance s'écrit : l T ( ) ( ) / 2 1/ 2 ' 1 ? n ? ? ? 1 ? ? r g , / 2 exp = ? - ? ? - ? - H - r H r t t t t t ? 2 t = 1 ? ? ? ? Où rt désigne l'actif Car ? r t / t - 1 ? N n ? 0 n , H t ? ? ? ? ? ? ? Ainsi on aura la fonction de vraisemblance logarithmique : ( T ? ? n / 2 1/ 2 ' 1 ? ? ? 1 - - log , / log 2 exp l ( ) ( ) 0 ? & g = i - t ? ? ? ? H r H r
- fl t t t t ? ? ? 2 t = 1 ? ? ? ? = - T 1 ? 2 1 t = ( ) n H r H r ' 1 - log 2 log g + + t t t t On sait que H t = D t R t D t et 1 s t D t - r t = , en remplaçant Ht par l'expression D t R t D t on aura : T
( ) ( ) 1 ' 1 1 1 - - - log , / log 2 log l n D R D r D R D r 0 çb e g = - + + ? t = 1 t t t t t t t t t 2 = - T 1 ? 2 1 = t ( ) n D R R g e e ' 1 - log 2 2log log + + + t t t t t T Avec cette fonction log-vraisemblance il est très difficile d'estimer les paramètres pour des matrices de grandes tailles. Alors Engle (2002) propose une estimation en deux étapes permettant une estimation consistante des paramètres. Soit ( ) ( 1 L l O çb c n g D r D r c c R ? R ? = = - ? + + - + + ' 2 ' ' 1 - log , / log 2 2log log - ) t t t t t t t t t t t t=1 2 Donc Engle propose de diviser l'estimation en deux étapes : une partie dépend des paramètres de la volatilité et la seconde partie dépend à la fois des paramètres des corrélations conditionnelles et des paramètres de la volatilité. Ainsi la fonction log-vraisemblance s'écrit : L ? ? ? = l ? ? ? t = L v ? ? t + L c ? ? ? t ( , / t ) log ( , / ) ( / ) ( , / ) T comprend les paramètres de la Avec ( ) ( ) L O e n ,r D r D - r 1 ' 2 / log 2 2log = - ? + + v t t t t t t = 1 2 volatilité( Dt ) . T Et ( ) ( ) 1 L O çb e R e e e R e ' ' 1 comprend les paramètres de la corrélation - , / log = - - + c t t t t t t t 2 t = 1 conditionnelle( Rt ) . Pour déterminer O $ et ? $ on cherche à maximiser la fonction log-vraisemblance ce qui revient à max { L v ( / t ) } O O e et max { L c ( u , / t ) } ? O 7 e Etape 1 : Dans cette première étape d'estimation, un modèle GARCH (p, q) univarié est appliqué aux variances conditionnelles de chaque actif. A l'issue de celle-ci, les coefficients qui expliquent la volatilité de chaque actif pris individuellement sont obtenus en résolvant le problème max{L v ( / t ) } O O e . Pour la résolution voir chapitre 4. Etape 2 : Dans cette seconde phase d'estimation, les coefficients des volatilités obtenus lors de la première étape, O $ sont maintenant supposés connus et servent à conditionner la fonction de vraisemblance utilisée pour estimer les paramètres q$ de la dynamique de corrélation. Cette procédure réduit grandement le temps de calcul mais au prix d'une perte d'efficacité dans la mesure où ce n'est qu'une partie de la vraisemblance, celle des corrélations qui est maximisée lors de la seconde étape. max { L c ( u , / t ) } IV.2 Estimation de la corrélation conditionnelle Dans la deuxième étape d'estimation, les paramètres de la corrélation dynamique sont obtenus par diverses méthodes. Méthode 1 (le lissage exponentiel) T t s - . e e s 1, 2, ? ? u 1,2 s = 1
t T T ? ?? ? s s 2 2 ? ?? ? ? ? ? e ? e 1, 2, = = 1 1 C'est-à-dire . u ( )( ) ( )
= = - ? ? - ? - + ? - q où q 1,2, ? t , 1 1,2 , , , 1 , 1 , , 1 q t i j t i t j t i j t q q 1,1, 2,2, t t L'estimateur obtenu est appelé DCC LL INT a + fi =1. Méthode 2 (le Mean Reverting) . u ( ) ( ) ( ) q où q 1,2, ? = = ? - a - fi + a ? - ? - + fi - t , 1 1,2 , , , , 1 , 1 , , 1
q t i j t i j i t j t i j t q q 1,1, 2,2, t t Où ? i , j est la corrélation inconditionnelle Dans cette partie on estime les paramètres des corrélations, L'estimateur obtenu est appelé DCC LL MR si et seulementa +fi <1. On retrouve l'estimateur DCC LL INT lorsque a + fi =1. Modèle de corrélation simple Les modèles de corrélation simple d'Engle s'écrit sous la forme : Q t t t t = ( 1 - )( ? - 1 ? ' - 1 )+ Â - 1 Q pour DCC LL INT Q R t t t t = ( 1 - a - fi ) + a ( ? - 1 ? ' - 1 ) + fi - 1 Q pour DCC LL MR R est la matrice de corrélation inconditionnelle Donc la matrice est obtenue par - 1 / 2 R t = ( ) ( ) d i a g Q t Q t d i a g Q t 1 / 2 - V.2 Propriétés asymptotiques de la méthode du PMV Sous des conditions de régularité supplémentaires portant notamment sur les variances conditionnelles du score et sur la stationnarité du processus observé, on peut alors établir que l'estimateur du pseudo-maximum de vraisemblance est asymptotiquement convergent et asymptotiquement normal :
T ? t ? N I - JI - ( u ) ( 1 1 ) - ??> d 0, ( ? ? 2 lo g ( l t ( ) 9 0 Où I E O = ? ? 0 ? ? ? ? ' ? ? ? ? a ? log( l t ( ) log( l t ( ) O O = ? ? 0 0 J EO 0 ? ? ? O O ' V. Approche théorique de la gestion de portefeuille : Introduction Au cours des dix dernières années, on a assisté à un renversement des perspectives au niveau de la gestion de portefeuille. Au lieu de considérer le portefeuille comme étant une somme d'éléments, c'est le portefeuille lui-même qui est devenu l'élément de base, les inter relations entre ces composantes prenant autant d'importance que la qualité intrinsèque de chacune d'entre elles. La théorie moderne de portefeuille a été la base de ce renversement. Forgée au début des années cinquante par Harry Markowitz, elle sera reprise, développée et surtout conduite jusqu'à son application pratique par W. Sharpe et par d'autres dans la fin des années soixante. C'est pour la première fois que Markowitz et ses successeurs s'attaquaient à une rationalisation complète de tous les problèmes de gestion de portefeuille et construisaient une théorie globale où rien apparemment n'était laissé dans l'ombre. Dans cette partie, on va introduire la théorie de gestion quantitative de portefeuille, en commençant par la théorie de Markowitz qui est la théorie fondatrice de ce domaine, en suite on introduit le concept de corrélation qui est sûrement l'un des outils les plus importants dans la gestion de portefeuille, d'où l'intérêt majeur d'estimation des matrices variance-covariance à partir des modèles GARCH-DCC au lieu des matrices de variance covariance empiriques. V.1 Théorie de Markovwitz La gestion de portefeuille est née en 1952 à la suite d'un article de H.Markowitz. Il s'agit d'une discipline appartenant à la finance quantitative. La théorie de Markowitz propose de maximiser la performance du rendement global d'un portefeuille en minimisant son risque. Comme mesure de performance et de risque cette théorie utilise l'espérance et la variance du portefeuille calculées à partir des espérances et variances des actifs composants celui-ci, supposées connues. Pour chaque actif i=1 ,. . . ,n, ì désigne l'espérance de gain, ó la variance. Pour deux actifs ñ est 2 i i ij le coefficient de corrélation. Si nous représentons par Xi la proportion du capital investi sur l'actif i, l'espérance et la variance du portefeuille X= (X1, ,Xn ) sont données par : ( ) X = ? n x x t = i i i_L i_L E i ? 1
? = Q = p a a pour i ~ j et Q ii = ? i 2 Où ii 1, ij ij i j Pour l'investisseur désirant prendre le moins de risque possible, l'objectif est donc de minimiser la variance du portefeuille. D'autre part, de manière à garantir un rendement minimum b (choisi par l'investisseur), la contrainte suivante doit être tenue en compte : ~ ì Xb.De plus, étant donné que Xi t représente un pourcentage du capital on a : t e X=1 (où e est le vecteur unité). Le problème d'optimisation auquel est confronté l'investisseur est donc :
1 ? = e t X ? ? ? ~ X 0 ? u X b t> V.2 Définition d'un portefeuille C'est la combinaison d'un ensemble de titres possédant des caractéristiques différentes en matière de valeur et de perception de dividendes. Cette combinaison se fait en des proportions différentes afin d'avoir un portefeuille bien diversifié permettant de réaliser un rendement espéré bien déterminé tout en minimisant le risque que peut courir l'investisseur. Mathématiquement un portefeuille P est un vecteur de proportions Xi relatives chacune à la proportion du capital investi dans chaque titre. ? ? X1 ? ? ? ? . ? ? . P = X ? ? ? ? i ? ? . ? ? ? ? ? ? Xn Avec i part du capital investi dans l'actif i X = capital total Rendements d'un titre : Le taux de rendement d'une action est la mesure de la rentabilité qu'elle a procurée au cours d'une période donnée. Formellement le rendement d'une action se calcule comme suit : Soit Pt , le prix d'un actif à la date t et Rt le logarithme du rendement correspondant : RP P t t t = log - log -1 log ( ) Où Dt p p t - t -1 1 + D t p t = désigne la variation de prix. -1 Rendements d'un portefeuille : n R = X R p t t ? t=1 C'est la moyenne des rendements des titres constituant le portefeuille pondérés par leurs proportions dans le portefeuille. On peut également calculer le rendement d'un portefeuille en se basant sur sa valeur. Le calcul se fait de la manière suivante : V - V t t-1 R = p V t-1 Avec Vt : valeur du portefeuille à la date t Vt-1 : valeur du portefeuille à la date t-1 Risque d'un portefeuille et attitude de l'investisseur : 1. Mesure de risque : Les taux de rendements successifs d'une action ou d'un portefeuille peuvent avoir d'importantes fluctuations autour de leur valeur moyenne. Pour mesurer ce risque, dont l'origine revient à ces fluctuations, on a recours à l'écart type ou la variance des rendements par période. La variance de l'action sur T périodes est : 1 ó = T i T ? ? ) R - R i,t i t=1 2 Avec Ri,t : le taux rendement de l'action i au cours de la période t. Ri :la moyenne arithmétique des taux de rendement. Si, par ailleurs, on veut connaître le lien qui existe entre les fluctuations des taux de rendement de deux actions i et j il faut recourir à la covariance.
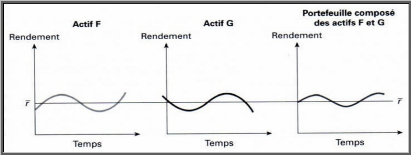
n n ?? ( ) ( ) i=1 j=1 R - R R - R i,t i j,t j L'interprétation de la covariance est liée à son signe. En effet si la covariance est positive alors on peut dire que les taux de rendement des actions i et j évoluent dans le même sens et si la covariance est négative alors les deux taux évoluent dans deux sens contraires. Enfin si la covariance est nulle alors on conclura qu'il n'y a aucune relation entre les évolutions des rendements deux titres. On pourrait aussi définir un troisième concept qui est le coefficient de corrélation qui s'obtient en rapportant la covariance au produit des écarts type des taux de rendement des titres i et j. = ó , C e coefficien t est com pris entre -1 et 1 . ij ñ ij i j óó Si le coefficient de corrélation est positif alors les
taux de rendements des actifs i et j ont deux variables deviennent proportionnelles. Et si ñij est négatif alors les deux variables ont tendance à varier dans un sens opposé. Plus ce coefficient se rapproche de -1 plus leurs variations en valeur absolue deviennent proportionnelles. En fin, une corrélation nulle indique qu'il n'y a pas de relation entre les taux de rendements des titres considérés. 2. Risque d'un portefeuille : Nous avons présenté la technique utilisée pour la mesure du risque d'un titre. Dans cette partie on va s'intéresser au risque total du portefeuille. Pour un portefeuille qui se compose de N titres, son taux de rendement dépendra à la fois des taux rendements des différents titres et aussi de leurs différentes proportions. N
i= 1 N Donc : ? E(Rp) = X E(R ) i i i=1 Et : ó 2 2 2 2 2 p 1 1 1 2 1,2 1 N 1,N 2 2 2 1 2,1 = X ó +X X ó +....+X X ó +X ó +X X ó +.... ...+X ó +X X ó +X X ó +.... 2 2 N N N 2 N,2 N 1 N,1 NN On peut aussi obtenir : ó = X X ñ ó ó 2 p i j ?? i j i j i=1 j=1 Cette dernière expression de la variance renseigne sur le lien étroit entre le risque du portefeuille et la corrélation existant entre les rendements des titres le constituant. Par ailleurs on peut définir un autre concept qui est la contribution d'un titre au risque du portefeuille. En effet la variance peut s'écrire : ? ? ? ? 2 2 2 2 2 2 2 ó =X X ó ... X ó ... X ó ... X X ó ... X ó ... X ó .. ? ? ? ? ? ? ? ? ? ? ? p i N i i i 1 1 1 1,i 1,N 1 i,1 N i,N ( ) X ó ... X ó ... X ó 2 2 2 1 N,1 N,i N N + + + + i .. . X + N La contribution du titre i dans le risque est alors : X i X 1 ó i,1 ... X i ó i ... X N ó i,N C'est la contribution absolue, elle dépend de trois ( + + + + ) 2 2 2 facteurs : V' La variance de son rendement V' La covariance du titre avec les autres titres V' La proportion du titre dans le portefeuille 3. Corrélation et diversification : La corrélation est sûrement l'un des outils les plus importants utilisé dans la gestion de portefeuille, car elle sert à déterminer si les rendements de différents placements dans un portefeuille réagissent de façon identique ou opposée en fonction des conditions économiques. En statistiques, le degré de corrélation est le degré d'association entre 2 variables aléatoires. Mathématiquement et aussi en finances, la corrélation est exprimée par un coefficient de corrélation qui varie entre -1 (pas de corrélation) en passant par 0 (tout à fait indépendant) et +1(corrélation maximale). Cependant, il est important de ne pas confondre corrélation avec causalité. Depuis l'avènement de la théorie de la gestion moderne du portefeuille, il y a 50 ans, la règle d'or dans la constitution d'un portefeuille consiste à combiner diverses catégories d'actif qui affichent la plus faible corrélation possible entre elles. Bien que cette règle soit valide a priori, on a eu tendance à oublier qu'une forte corrélation des rendements entre les divers actifs n'équivaut pas nécessairement à des rendements similaires. Un peu de technique L'analyse de corrélation consiste à mesurer l'interrelation entre deux variables; le résultat de cette mesure s'appelle «le coefficient de corrélation». La mesure d'un coefficient de corrélation peut varier entre +1 et -1. Un coefficient de +1 représente une corrélation positive parfaite, alors qu'un coefficient de -1 représente une corrélation négative parfaite, ce qui signifie de façon générale que les deux variables (ex : rendement de deux placements) réagiront de façon opposée face à un même événement. Il existe une règle générale pour évaluer le coefficient de corrélation de différents actifs ou placements : Corrélation élevée Plus de 0.75; cette mesure implique que les deux actifs réagissent de façon très similaire aux conditions du marché et que leurs rendements iront généralement dans la même direction. Corrélation modérée Entre 0.25 et 0.75; implique que les deux actifs répondent de façon assez similaire aux conditions du marché, mais que leurs rendements pourront évoluer plus ou moins dans la même direction. Corrélation basse Entre 0.00 et 0.25; les deux actifs réagissent différemment aux conditions du marché et leurs rendements ont tendance à demeurer indépendants l'un de l'autre. Corrélation négative Moins de 0.00; les actifs réagissent différemment aux conditions du marché et leurs rendements évoluent en direction opposée. Diversification du risque Afin de réduire le risque total d'un portefeuille, il est préférable de combiner des actifs présentant une corrélation négative ou légèrement positive. Une combinaison d'actifs entretenant une corrélation négative parfaite permet en effet d'éliminer la variabilité du rendement du portefeuille, c'est-à-dire son risque.
Corrélation entre les séries M, N et P. Les séries présentant une corrélation positive parfaite, M et P, sur le graphique de gauche varient dans le même sens. En revanche, les séries présentant une corrélation négative parfaite, M et N sur le graphique de droite, varient en sens diamétralement opposé.
Combiner des actifs corrélés négativement afin de diversifier les risques. Le risque lié à la variabilité des rendements résultant de la combinaison d'actifs corrélés négativement, F et G, dotés du même rendement espéré, r, donnent un portefeuille (graphique de droite) et ayant le même rendement espéré mais avec un facteur de risque moindre. Certains actifs ne sont pas corrélés : ils ne présentent aucune liaison et leurs rendements respectifs sont totalement indépendants. La combinaison d'actifs non corrélait permet également de réduire le risque (certes, cette méthode n'est pas aussi efficace que la combinaison d'actifs corrélés négativement, mais elle est toujours plus que la combinaison d'actifs corrélés positivement dans la parenthèse. Les actifs non corrélés présentent un coefficient de corrélation égale à 0, point médian entre une corrélation positive parfaite et une corrélation négative parfaite. Conclusion : Donc, lors du choix du portefeuille, l'investisseur doit prendre en compte ces trois facteurs pour bien gérer son risque. Dans notre mémoire les deux premiers facteurs ont été pris en compte dans un contexte des modèles GARCH multivariés, plus précisément le modèle GARCH-DCC qui prend en considération l'interdépendance entre les actifs, cela en permettant à la matrice de corrélation d'être dynamique dans le temps. Donc à chaque fois on peut refaire l'optimisation pour obtenir une meilleure diversification. Application de la méthode multivariée Le but de cette application est d'estimer deux types de modèles GARCH multivariés: CCC (Constant Conditional Correlation) et DCC (Dynamic Conditional Correlation). Les données journalières utilisées sont les indices de prix : QQQQ, SPY, GLD, IEV et l'indice ajouté dans cette partie OIH. L'analyse des données journalières couvre la période de 03 janvier 2005 au 30 novembre 2007, ce qui nous donne 780 observations par marché. Ces indices sont pris en dollar américain. Ils ont été extraits de la base de données Yahoo finance. L'échantillon est constitué de 5 marchés dont 2 américains (QQQQ et SPY), 2 internationaux (GLD et OIH) et le dernier IEV qui représente le marché européen. Statistique descriptive
Le tableau ci-dessus affiche un ensemble de statistiques descriptives des variables de nos séries. Les distributions des cinq actifs sont significativement différentes de la distribution normale au seuil de 5%. Ces séries sont caractérisées par des coefficients d'aplatissement suffisamment supérieurs à celui de la loi normale. Elles présentent également des coefficients d'asymétrie différents de celui d'une distribution normale. La négativité des coefficients d'asymétrie pour les séries indique que ces branches d'activités ont subi plus de chocs négatifs que de chocs positifs durant la période analysée. Les spécifications GARCH adoptées sont susceptibles d'expliquer une part significative de la non-normalité de ces séries. En effet, l'application du test Jarque-Bera aux séries de rendements révèle la non-normalité des séries qui s'explique par la présence des effets GARCH. Analyse graphique
Le graphe précèdent représente l'évolution des prix des actifs, sur le marché boursier. Un examen minutieux des changements à court terme (une semaine) fait apparaître de nombreux pics compensés souvent par des creux, plus précisément des variations traduisant la forte volatilité des prix boursiers. Traitement logarithmique Quand il s'agit des prix, la transformation des données par l'introduction des rendements logarithmiques est très fréquente ; en particulier, elle est utilisée lorsqu'on constate que la série chronologique a une forte variabilité instantanée ou si elle est affectée d'une tendance. En plus du fait que les rendements sont généralement stationnaires, une propriété que ne possède pas les séries prix.
Estimation du modèle CCC La méthodologie du modèle CCC de Bollerslev (1990) qui est le précurseur du DCC de Engel (2002) consiste à estimer en premier : - la variance conditionnelle de chaque actif avec un modèle de type GARCH. Une matrice diagonale contenant ces variances conditionnelles est construite, la racine carrée de cette matrice donne une matrice diagonale des écart-types conditionnels Dt des actifs étudiés. Le calcul de la matrice de variances covariances conditionnelles Ht est obtenue par le produit de trois matrices : la matrice diagonale des écart-types conditionnels Dt , la matrice R de corrélation entre les variables et la matrice diagonale des écart-types conditionnels Dt . Le modèle s'écrit de la manière suivante : IL HD RD t t t = Ddiag= t R p = ij , 1 avec ? ? ii ( 11 , 22 ,..., ) h h h t t NNt
Estimation Pour des raisons de parcimonie et de simplicité, le modèle GARCH (1,1) de Bollerslev est une réponse sur-mesure, puisqu'il est équivalent à un modèle ARCH d'ordre infini. En effet ce dernier intègre toute l'information avec moins de paramètres à estimer. La première étape de la procédure utilisée dans Engle (2002) renvoie à l'estimation d'un GARCH pour chacune des séries. Afin d'obtenir les paramètres p et q des GARCH univariés, on a utilisé l'approche Box-Jenkings (1976) qu'on a appliqué à chacune des 5 séries:
monter le prix du pétrole. Les sociétés technologiques (QQQQ) dépendent moins du pétrole puisqu'elles sont fondées sur l'innovation et moins sur les grandes infrastructures de fabrication consommatrice d'énergie comme les usines ce qui explique une corrélation plus faible de 38,49 %. s Les coefficients de corrélation entre l'indice de l'or (GLD) et les sociétés américaines (SPY, QQQQ) sont faibles et parfois moyen avec IEV et OIH. Cela s'explique par le fait qu'en période de crise boursière l'or, qui est considéré comme une valeur sûre (refuge), monte de manière importante. Dans une période de crise persistante, les valeurs qui montent ensuite sont les matières premières, comme le pétrole, suivi des valeurs des sociétés européennes. Cela explique une corrélation de 3 5,58% entre GLD et OIH et de 40,17% entre GLD et IEV. Ces dernières sont recherchées comme alternatives aux sociétés américaines. Cependant, le coefficient de corrélation le plus faible est de 12,6 1% entre GLD et QQQQ et 19,03 % entre GLD et SPY. Cela traduit la politique de la réserve fédérale américaine qui a décidé de dépareiller sa monnaie de la valeur de l'or dans les années 80 pour démontrer la force de son économie. Cette faible corrélation démontre que l'économie américaine est suffisamment forte pour ne pas dépendre de la valeur de l'or. Matrice de variance covariance à l'instant t =1 : GLD GLD 0,1043 ? OIH ? SPY ? IEV QQQQ ? OIH
Matrice de variance covariance à l'instant t = 780 :
GLD OIH SPY IEV QQQQ GLD 0,1826 0,0883 0,0238 0,05 0,0177 ? OIH 0,337 0,0871 0,082 0,0735 ? SPY0,0853 0,069 0,08 16 ? IEV0,0848 0,0644 QQQQ ? 0,1083 On remarque de ces deux tableaux précédents que la matrice de variance covariance varie au cours du temps, cela est dû certainement aux fortes fluctuations de la volatilité de chaque indice, car la matrice de corrélation est supposée constante dans le modèle CCC. Prévision de la matrice variance covariance à l'instant t = 781 :
On sait que H t = D t RD t , alors u u u H t + 1 = D t + 1 R D t + 1 , où u $ $ $ D t + 1 = diag ( h 11t+1, h 22t+1 ,..., h 55t+1), donc pour faire la prévision de la matrice variance covariance, il suffit seulement de prévoir la matrice de variances conditionnelles, d'où : 0 ? ? 0 ? 0 ? 0 ? 0.0105 ? D u781
Donc on obtient la matrice variance covariance suivante :
GLD OIH SPY IEV QQQQ GLD 0,1741 0,0856 0,0226 0,0526 0,0175 ? OIH 0,3326 0,0844 0,0878 0,0737 ? SPY0,0812 0,0726 0,0803 ? IEV0,0985 0,0701 QQQQ ? 0,1103 Test de constance de corrélation Analyse graphique : Les graphes ci-dessous affichent les niveaux des corrélations conditionnelles dynamiques estimés selon l'approche de Engle (2002). A l'observation de l'évolution de ces corrélations, il semble que ces dernières affichent des tendances variées qui laissent présager que les interprétations basées sur l'hypothèse de constance des corrélations seraient erronées.
Mise en oeuvre du test : Divers tests statistiques furent développés pour tester l'hypothèse de constance des corrélations entre une structure dynamique de celles-ci. Le test proposé par Engle et Sheppard (2001) est implémenté dans cette analyse. Sous l'hypothèse nulle, ce test suit asymptotiquement une distribution Khi deux à (p+1) degrés de liberté. Les hypothèses du test sont les suivantes : p H0 :R t =R,VtE T Contre 1 ( ) ( ) ( ) H Vech R Vech R Vech R u u : J3 ? u = +? t i t i i= 1 On effectue le test de Engle et Sheppard (2001) sur les 5 séries, en gardant la même hypothèse de départ concernant la structure de la variance, c'est-à-dire qu'elle suit un processus GARCH (1,1). Aussi on teste la présence d'autocorrélation dans la matrice de corrélation avec un retard. Le tableau suivant présente les résultats du test. Test de Engle et Sheppard (2001)
Les conclusions du tableau ci-dessus sont claires, on rejette l'hypothèse que la corrélation est constante dans l'échantillon. La modélisation DCC semblerait plus appropriée afin de capturer l'évolution dynamique de la matrice de corrélation. Estimation du modèle DCC Comme on l'a signalé dans le chapitre 5, l'estimation des paramètres se fait en deux étapes, la première concerne la partie de volatilité O, la seconde étape pour la partie corrélation dynamique. Dans la première étape d'estimation, un modèle GARCH (1,1) est appliqué aux variances conditionnelles de chaque actif. A l'issu de celle-ci les coefficients qui expliquent la volatilité pour les 5 séries prisent individuellement sont affichés sur le tableau suivant :
Ces paramètres sont estimés à l'aide de la fonction Dcc-Mvgarch11. Interprétation Sur les marchés boursiers, il existe, en général, une persistance (á + â) proche de l'unité, malgré la contrainte (á + â) < 1 imposée. Ceci étant, la série qui a une volatilité plus sensible aux innovations que les autres (á élevé) est IEV avec une valeur égale à 0,16. Inversement, OIH a une volatilité qui semble moins affectée par les chocs. Les autres séries (GLD, SPY et QQQQ) ont une sensibilité aux chocs oscillant entre [0,06 0,095]. En ce qui concerne les effets autorégressifs de ces volatilités, on remarque qu'il est dans l'ensemble supérieur à 0,80, sauf pour IEV où il n'est que de 0,72; et inférieur à 0,96. La série GLD a le coefficient autorégressif le plus élevé (0,9288) ce qui explique la forte variation des rendements. Remarque Les paramètres obtenus par la fonction Dcc-MVGARCH sont identiques à ceux obtenus par la modélisation des séries de rendements. Pour estimer la matrice de corrélation temporelle DCC, on commence par calculer la matrice de variance covariance conditionnelle Qt des résidus standardisés qui s'écrit de la forme suivante : Q = -- a - /3 Q + a e t e t + /3 Q t ? t 1 1 ( ) ( ) ' 11 Programme MATLAB disponible sur le site de http://www.kevinsheppard.com/research/MatlabAtlas/MatlabAtlas.htm Application :
La matrice Qt à l'instant t = 780
Après calcul de la matrice Qt , on modélise la matrice Rt de la manière suivante : ? 1 / 2 ? 1 / 2 R t = ( ) ( ) diagQ t Q t diagQ t
Prévision de la matrice de corrélation à l'instant t = 781
Paramètres de la partie corrélation
On constate qu'à l'image de la majeure partie des séries d'actifs à l'étude, les corrélations conditionnelles dynamiques ont un effet autorégressif inférieur à 0,94. Pour ce qui est de la sensibilité aux chocs de nos corrélations, elle est moins importante que celle que l'on trouve pour les 5 séries ci-dessus (0.01853). On a, par conséquent, une volatilité avec une sensibilité aux chocs beaucoup plus forte pour les corrélations comparativement à celle des rendements d'actifs. Simulation par backtesting de stratégies d'investissementsIntroduction : Dans ce chapitre, nous allons présenter la partie pratique de notre mémoire. Cette partie consiste à présenter un programme, que nous avons réalisé en Matlab, qui permet d'effectuer une opération appelée dans le monde de la finance, le Backtesting. Cette opération, consiste à simuler dans le passé une stratégie d'allocation de portefeuille, c'est-à-dire une manière d'attribuer des poids à chacun des actifs du portefeuille au cours du temps. Elle permet en particulier, de vérifier de manière empirique, comment une stratégie donnée se serait comportée dans des conditions réelles en se plaçant dans le passé sur une période donnée. Description du Backtesting effectué L'opération de backtesting consiste à simuler dans des conditions réelles une stratégie d'allocation de portefeuille. Elle consiste à choisir une date particulière dans le passé, à allouer un capital donné (une somme d'argent) dans un portefeuille à cette date en utilisant la formule d'optimisation introduite dans le chapitre précédent. Elle consiste ensuite à réallouer le capital du portefeuille chaque semaine ou chaque mois, c'est à dire avec une fréquence donnée. On imite ainsi un gestionnaire de fond qui, en fonction de l'évolution du marché va attribuer son capital en prenant en compte les variations de prix constatées sur les marchés le dernier mois ou les dernières semaines. Dans notre cas, ces variations sont traduites par le calcul de nouveaux rendements espères pour chacun des actifs et d'une nouvelle matrice de corrélation estimée selon la méthode GARCH DCC. Celle-ci prends en compte les données des prix des actifs depuis la date initiale jusqu'à la date de réallocation. Les valeurs se trouvant après la date de réallocation ne peuvent effectivement pas être prises en compte puisqu'elles se trouvent dans le futur à ce moment-là. Dans notre cas pratique, nous avons choisi de tester notre approche sur le portefeuille composé de GLD, OIH, SPY, IEV et QQQQ introduits précédemment. Nous avons effectué le Backtesting sur une période allant de janvier 2005 à décembre 2007, avec une réallocation des poids tous les mois (22 jours ouvrables). La réallocation, c'est-à-dire le nouveau calcul des poids est effectué en fonction des mesures de performances (rendements espérés) et du risque estimé sous forme de la matrice de corrélation calculée au moyen de la méthode GARCH DCC. A la première date du backtesting, on suppose que le capital initial du portefeuille est de 100 unités. On réalise une opération d'optimisation qui donnera pour chaque actif un poids donné. Le capital investit sur chaque actif correspondra au capital initial multiplié par le poids correspondant. Ensuite, les jours suivants la valeur de ce portefeuille va évoluer. En effet, chaque jour séparant deux allocations, les poids vont rester constants mais les prix des différents actifs vont évoluer sur les marchés. Ces variations de prix vont donner, chaque jour, une nouvelle valeur au capital investit dans chaque actif et donc au portefeuille. La nouvelle valeur du portefeuille correspond à la somme des nouvelles valeurs des capitaux investis dans chaque actif. Les jours prochains, la valeur du portefeuille va changer conformément au changement des prix des actifs détenus dans le portefeuille. Lors d'une nouvelle période de réallocation, nous calculons la valeur du portefeuille le jour précédent de la réallocation. Nous calculons de nouveaux poids au moyen d'une nouvelle opération d'optimisation et le nouveau capital du portefeuille est réparti sur les différents actifs et ainsi de suite jusqu'à la fin de la période de backtesting. Afin de comparer l'efficacité de l'optimisation en utilisant la méthode GARCH DCC, nous allons calculer la valeur du portefeuille en utilisant en parallèle une méthode d'optimisation qui utilise une matrice de corrélation empirique. Pour les deux méthodes, tous les paramètres d'optimisation seront les mêmes mis a part la matrice de corrélation. Nous allons également supposer que le capital initial est de 100 unités pour les deux portefeuilles ce qui permettra de les comparer par la suite sur une base commune. Un portefeuille qui vaudra 120 unités à la fin du backtesting correspondra à un portefeuille dont la valeur aura augmenté de 20% sur cette période. La fonction de backtesting que nous avons réalisé est la suivante : [PortA_NAV, PortB_NAV, PortWtsA, PortWtsB] = backtesting (NAV, Window, StartDate, EndDate, Frequency). Le programme matlab function [TickSeries, PortA_NAV, PortB_NAV, PortWtsA ,PortWtsB] = backtesting(NAV, Window, StartDate, EndDate, Frequency) % % Backtesting simulation (Mean-Variance optimization) % % Inputs % NAV : market data (price or Net Asset value) % Window : estimation window % StartDate : backtesting begin % EndDate : backtesting end % Frequency : rebalancing frequency % Outputs % TickSeries : NAV (base 100) of assets % PortA_NAV : NAV of optimal portfolio with empirical cov. matrix % PortB_NAV : NAV of optimal portfolio with GARCH cov. matrix % PortWtsA : optimal weights of portfolio with empirical
cov. % PortWtsB : optimal weights of portfolio with GARCH cov. matrix % % Example % backtesting(NAV, 250, 250, 779, 22) % % author: Khaled Layaida, M.Allamine Alhabo, (2008) % % get/load data ETFs %disp('Load Market Data ...'); %addpath . /market_data %load serie % log-returns serie = price2ret(NAV); % number of dates and number of assets [NumDates, NumAssets] = size(serie); % tests if (Window < 12) disp('Input error - the input parameter window is too small ! Window >= 12 pts'); return; end; if (StartDate < Window) disp('Input error - the start date of the backtesting is smaller than window estimation !'); return; end; if (StartDate > (EndDate-2)) disp('Input error - the end date of the backtesting must be bigger than start date + 1 !'); return; end; % backtesting parameters NumOpt = floor((NumDates-StartDate)/Frequency + 1); % number of rebalancing (optimization) % Quadratic programming options options = optimset('quadprog'); options = optimset(options, 'LargeScale','off'); f = zeros(NumAssets,1); % linear part Aeq = ones(1,NumAssets); % matrix of equalities constraints beq = ones(1,1); % vector of equalities constraints lb = zeros(NumAssets,1); % lower bounds ub = 0.5*ones(NumAssets,1); % upper bounds % initialisation PortWtsA = [] ; % weights of portfolio A PortRiskA = []; PortReturnA = []; PortWtsB = [] ; % weights of portfolio B PortRiskB = []; PortReturnB = []; normFro = []; % backtest loop: Start date -> End date ii = 0; %sprintf('Backtest ... with %i', NumOpt, ' rebalancing ...'); for k = 1:NumOpt % use subdata for rebalancing ii index = ii*Frequency + StartDate + 1 - Window : ii*Frequency + StartDate; RetSeries = serie(index,:); % cumulative estimation window (for GARCH) index_cum = 1 : ii*Frequency + StartDate; RetSeriesGARCH = serie (index_cum,:); ii = ii + 1; % expected returns and empirical cov. matrix [ExpReturn, ExpCovariance] = ewstats(RetSeries); % GARCH cov. matrix [ExpCovarianceGARCH] = covGARCH (RetSeriesGARCH); % Frobenius-norm of matrix covDif f = ExpCovariance-ExpCovarianceGARCH; normFro = [normFro, norm(covDiff,'fro')]; % target return TargetReturn = -10000; %TargetReturn = mean(ExpReturn); %TargetReturn = 20000; % Mean-Variance optimal portfolio % portfolio A (empirical cov. matrix) [WtsA, fval,exitflag, output, lambda] = quadprog(ExpCovariance, f, - ExpReturn,-TargetReturn,Aeq,beq,lb,ub,[] ,options); PortWtsA = [ PortWtsA, WtsA]; PortRiskA = [ PortRiskA, sqrt(WtsA'*ExpCovariance*WtsA)]; PortReturnA = [ PortReturnA, ExpReturn*WtsA]; % portfolio B (GARCH cov. matrix) [WtsB, fval,exitflag, output, lambda] = quadprog(ExpCovarianceGARCH, f, - ExpReturn,-TargetReturn,Aeq,beq,lb,ub,[] ,options); PortWtsB = [ PortWtsB, WtsB]; PortRiskB = [ PortRiskB, sqrt(WtsB'*ExpCovarianceGARCH*WtsB)]; PortReturnB = [ PortReturnB, ExpReturn*WtsB]; end % returns -> prices [TickSeries] = ret2price(serie(StartDate+1:EndDate,:)); % construct portfolio NAV
for k = 1:NumOpt-1 index = 1 + (k-1)*Frequency: k*Frequency; WtsA = []; WtsB = []; for i = 1:Frequency WtsA = [WtsA; PortWtsA(:,k)']; WtsB = [WtsB; PortWtsB (: , k) ']; end; PortA_NAV = [ PortA_NAV; coefA*sum(WtsA.*TickSeries(index,
:),2)]; if (k < (NumOpt -1)) coefA = PortA _NAV(k* Frequency) /sum(PortWtsA(: , k+1)'.*TickSeries (k*Frequency+1, :) , 2) ; coefB = PortB_NAV(k*Frequency) /sum(PortWtsB(: , k+1)'.*TickSeries (k*Frequency+1, :) , 2) ; end; end % portfolio log-returns PortA_ret = price2ret(PortA_NAV); PortB_ret = price2ret(PortB_NAV); [n, p] = size(PortA_NAV); % plot NAV hold on; title('Portfolios and Assets NAV'); xlabel ('Time'); ylabel('NAV (base 100)'); plot(100*PortA_NAV, 'b'); plot(100*PortB_NAV, 'r'); for k = 1:NumAssets plot(100*TickSeries(1:n,k), 'g'); end; hold off % % ex-post Perf. and Risk Analysis % % Total return % perfA = 100* (PortA_NAV(n)-PortA_NAV(1))/PortA_NAV(1); perfB = 100* (PortB_NAV(n)-PortB_NAV(1))/PortB_NAV(1); % Mean return % meanA = 100*mean(PortA_ret); % volatility % volatilityA = 100*STD(PortA_ret); % Value-at-Risk % %ValueAtRiskA = portvrisk(PortReturn, PortRisk, RiskThreshold,
PortValue); % display results disp('Total perf.% Mean% Vol%'); disp([perfA, meanA, volatilityA; perfB, meanB, volatilityB] ); End. Cette fonction permet de réaliser l'opération de backtesting et d'afficher le graphe des valeurs des portefeuilles calculés avec la méthode GARCH DCC et avec la méthode empirique. Les paramètres d'entrée de la fonction sont : NAV : la matrice qui contient les séries des prix des actifs. Window : la fréquence pour estimer la matrice empirique, cela veut dire que l'on prend 50 valeurs précédent la date d'allocation pour calculer la matrice empirique. StartDate : début du backtesting. EndDate : fin du backtesting. Frequency : fréquence de ré optimisation (ici on optimise chaque 22 jours). Les paramètres de sortie sont : TickSeries : valeurs de chaque actif à base 100. PortA_NAV : valeurs de chaque actif à base 100, avec la matrice empirique. PortB_NAV : valeurs de chaque actif à base, avec la matrice du GARCH DCC. PortWtsA : les proportions optimales du portefeuille avec la matrice empirique. PortWtsB : les proportions optimales du portefeuille avec la matrice GARCH DCC. L'opération de backtesting est effectuée dans Matlab au moyen de deux commandes :
En fin d'optimisation, on obtient les pourcentages d'allocation, ainsi que la valeur de chaque portefeuille à base 100. Application : Dans cette partie on va appliquer le backtesting en posant les contraintes suivantes :
Dans la suite de ce chapitre, nous allons donc appliquer ces trois opérations de backtesting et comparer les résultats avec la méthode empirique. Pour chaque test, nous allons afficher : le graphique des rendements des deux portefeuilles, la composition initiale et finale des portefeuilles ainsi que l'évolution de la composition du portefeuille au cours de la période du backtesting. Contrainte 1 : Maximum 50 % sur chaque actif Dans cette partie, on suppose que l'investisseur ne peut pas mettre plus de 50 % de son capital sur un seul actif, cela en posant cette contrainte dans le problème d'optimisation précèdent. Diagrammes en camembert : La méthode empirique : Ces diagrammes montrent la stratégie d'allocation initiale et finale de l'investisseur, et cela on se basant sur le programme d'optimisation quadratique, la matrice de corrélation utilisée dans cette partie est calculée empiriquement.
La méthode GARCH DCC : En prenant en compte la matrice GARCH DCC dans l'optimisation, on voit que les proportions d'investissement sont différentes à ceux de la méthode empirique, par exemple dans la partie empirique on a initialement 8% QQQQ et 42% GLD, mais dans cette partie on remarque une diminution de l'actif QQQQ (4%) aussi l'actif GLD avec 36%, aussi on voit que la proportion de l'actif SPY a diminué de 4% c'est-à-dire avec une proportion de 45%. Dans la période décembre 2007, on remarque que les proportions sont 45% GLD, 5% QQQQ et 50% SPY, alors qu'on ne possède pas de OIH et IEV dans le portefeuille.
Composition historique des portefeuilles Méthode empirique: Ce diagramme nous donne la composition historique du portefeuille après chaque allocation optimale (22 jours ouvrables), cette allocation est effectivement basée sur la minimisation de la volatilité, et cela en se basant sur la matrice de corrélation calculée empiriquement.
Tableau historique des allocations : Le tableau ci dessous affiche les différentes proportions de chaque actif durant toute la période du backtesting, il nous permet de voir les valeurs exactes des allocations après chaque optimisation mensuelle, avec la matrice calculée empiriquement.
Méthode GARCH DCC : On voit d'après cette composition historique, que la stratégie d'investissement est basée principalement sur l'action refuge GLD avec 50% du capital, et cela tout le long du backtesting, on remarque aussi que la proportion de SPY est aussi remarquable, par contre les autres actifs ne figurent pas avec des pourcentages considérables. Par exemple, on voit l'actif OIH figure dans le graphique en début de période, après il disparaît pour réapparaître entre avril et août 2007, dans cette période on voit aussi l'apparition de l'actif IEV avec les même proportions a peut prêt.
Proportions avec la matrice GARCH DCC : Le tableau ci-dessous affiche les valeurs du graphique précédent. On voit l'inclusion brusque des actifs OIH et IEV entre Avril et Juin 2007, cela a causé la diminution des parts de l'actif SPY dans le portefeuille. La proportion du GLD est de 50% pendant toute la période, elle désigne une valeur maximale que peut prendre cet actif.
Comparaison des valeurs historiques de chaque portefeuille :
On remarque d'après le graphique ci-dessus que le rendement du portefeuille avec la méthode GARCH DCC est nettement supérieur à celui de la méthode empirique, surtout dans les période de forte volatilité (entre le mois de février et septembre 2006), on remarque que dans cette partie le rendement est nettement meilleur, on peut donc affirmer que les modèles GARCH DCC sont puissant au sens de l'anticipation rapide de la corrélation, cette anticipation cause évidemment un changement rapide des allocations lors de l'optimisation. Contrainte 2 : Maximum 35 % sur chaque actif Dans cette partie, on suppose que l'investisseur ne peut pas mettre plus de 35 % de son capital sur un seul actif, cela en posant cette contrainte dans le problème d'optimisation précédent. On a posé cette nouvelle contrainte pour voire est ce que cette dernière peut changer les résultats de l'optimisation, c'est la méthode utilisée souvent par les gestionnaires de portefeuilles, cela pour forcer la diversification et diminuer ainsi le risque. Diagrammes en camembert : La méthode empirique : Ces diagrammes montrent la stratégie d'allocation initiale et finale de l'investisseur, et cela on se basant sur le programme d'optimisation quadratique, la matrice utilisée dans cette partie est calculée empiriquement.
On remarque que les proportions initiales et finales n'ont pas changé pratiquement, sauf pour le de IEV qui a diminué jusqu'à atteindre la valeur 0%, ce qui veut dire l'absence totale de cet actif, aussi l'augmentation de la proportion de l'actif QQQQ. Alors que l'actif OIH est depuis le début en 0%. La méthode GARCH DCC : Ici, les proportions de départ sont de 11% QQQQ, on remarque aussi qu'on a la même valeur de GLD 35%, mais dans cette partie l'actif OIH est inclus dans le portefeuille avec 19%, cela est peut être dû au pouvoir prédictif de la volatilité de la méthode GARCH DCC, c'est-à-dire que dans cette période on a eu sûrement une baisse remarquable de volatilité, ce qui implique a causé l'inclusion de cet actif dans cette méthode.
Composition historique des portefeuilles Méthode empirique : Ce diagramme nous donne la composition historique du portefeuille après chaque allocation optimale (chaque 22 jours ouvrables), cette allocation est effectivement basée sur la minimisation de la volatilité, on remarque que ce portefeuille se compose de 4 actifs, il est diversifié en plus grande partie entre QQQQ, SPY, GLD et une petite proportion de l'actif IEV. Tout le long de l'historique on remarque l'absence de l'actif OIH, et cela contrairement à la méthode GARCH DCC, c'est à cause des différences entre les matrices de corrélation.
Proportions avec la matrice empirique : Le tableau dans la page suivante affiche les différentes proportions de chaque actif durant toute la période du backtesting, il nous permet de voire les valeurs exactes des allocations après chaque optimisation mensuelle (22 jours ouvrables), avec la matrice calculée empiriquement. On voit que les proportions de la série OIH sont nulles tout le long du backtesting, celles de SPY sont constantes et maximales, puisque elles sont égales à la contrainte supposée (35%). Les autres actifs ont par contre des proportions variables dans le temps, et cela est dù aux changements de la volatilité du portefeuille.
Méthode GARCH DCC: Après diminution de la contrainte jusqu'à la valeur 35%, on remarque des changements significatifs dans les proportions, contrairement à la méthode empirique. Le changement principal est l'inclusion de l'actif OIH avec des proportions importantes, et cela tout le long de la période du backtesting, on voit aussi que les proportions de l'actif QQQQ ne sont pas les mêmes (dès fois nulles), par contre le premier portefeuille contenait de fortes proportions de QQQQ.
Proportions avec la méthode GARCH DCC : Le tableau suivant montre la différence significative entre les deux portefeuilles, au sens de diversification, cela est naturellement à cause des différences entre les matrice de corrélation, cette différence cause des changements dans l'optimisation, car elle est basée sur la minimisation de la volatilité qui s'écrit en fonction de la corrélation entre les rendements des différents actifs.
Comparaison des rendements historiques des deux portefeuilles : En posant la contrainte pas plus de 35%, le rendement des deux portefeuilles se rapprochent, mais celui de la méthode GARCH DCC reste toujours supérieur à celui de la méthode empirique. Le graphique suivant affiche les résultats :
Contrainte 3 : dans cette partie l'investisseur peut placer tout son capital sur un seul actif. Donc l'investisseur est exposé au risque de perdre toute fortune. Diagrammes en camembert : La méthode empirique : Ces diagrammes montrent la stratégie d'allocation initiale et finale de l'investisseur, et cela on se basant sur le programme d'optimisation quadratique, la matrice utilisée dans cette partie est calculée empiriquement, le programme d'optimisation n'est soumis à aucune contrainte, au sens que les proportions de chaque actif peuvent varier entre 0% et 100%.
On voit que cette fois le portefeuille est réparti initialement seulement sur les deux actifs SPY et GLD, avec les proportions respectivement 60% et 40%, ces deux actifs sont maintenus tout le long du backtesting, on peut voir cela avec les proportions finales sur le diagramme en camembert et le tableau historique des allocations ci-dessous. La méthode GARCH DCC : On voit que les proportions initiales de ce portefeuille sont de 15% OIH et 4% QQQQ, le reste du capital est réparti presque semblablement entre GLD et SPY. Juste après cette période on remarque la disparition de l'actif OIH du portefeuille.
Composition historique des portefeuilles : Méthode empirique : Dans cette partie, on voit que le portefeuille est panaché seulement entre l'actif SPY et GLD, la proportion de SPY est nettement plus grande que celle de GLD. On voit aussi une très faible proportion de QQQQ entre août et décembre 2007.
Allocations avec la méthode empirique : Le tableau ci-dessous montre bien que le portefeuille comporte seulement deux actifs, car les proportions des autres actifs sont toutes nulles.
La méthode GARCH DCC : Le diagramme suivant montre la composition historique du portefeuille en optimisant avec la matrice GARCH DCC, ce portefeuille est panaché seulement avec les actif SPY et GLD. L'actif OIH est inclus au début avec de petites proportions, mais après juin 2006 il ne fait plus partie de ce portefeuille. On voit aussi de très faibles proportions de QQQQ juste au début du backtesting.
Proportions avec la méthode GARCH DCC :
Comparaison des rendements historiques des deux portefeuilles : Comme dans les parties précédentes, on voit dans ce graphique le décalage nette entre les deux portefeuilles, la méthode GARCH DCC se comporte mieux que la méthode empirique même si on n'impose aucune contrainte. Donc on peut dire que la méthode GARCH DCC est meilleure que la méthode empirique utilisée souvent par la plupart des gestionnaires de portefeuilles financiers, et cela surtout dans les période de forte volatilité, par exemple dans la période entre mars et juin 2006 on voit que la courbe GARCH DCC en rouge est nettement supérieure à la courbe empirique (voire graphe ci-dessous).
Interprétation des résultats : Ces résultats montrent que les techniques qui tiennent compte des corrélations dynamiques performent mieux que les méthodes traditionnelles basées sur les corrélations empiriques. L'écart entre les niveaux de rendement produit par les opérations d'optimisation basées sur des matrices empiriques et DCC GARCH fait bien ressortir les différences très nettes. En particulier, en période de forte volatilité, le modèle DCC GARCH semble mieux anticiper le changement des corrélations. En effet, on remarque que lorsque la volatilité des marchés augmente dans les périodes suivantes :
Le graphique suivant affiche les rendements historiques des actifs tout le long du backtesting, il montre aussi les trois périodes volatiles que l'on a précisé précédemment.
Plutôt que de tenter d'interpréter la composition des portefeuilles lors du backtesting, opération difficile, nous allons tenter d'identifier la variation de la composition du portefeuille à des périodes clés. En effet, la composition du portefeuille évolue de manière plus importante dans ces périodes pour le portefeuille DCC GARCH que dans le cas empirique. La différence des rendements tout au long du backtesting permet de montrer que les rendements des portefeuilles GARCH sont quasi-systématiquement supérieurs à ceux de la méthode empirique. Cette supériorité demeure vraie lorsqu'on applique des contraintes sur les poids. Ces contraintes sont souvent utilisées par les gestionnaires de portefeuille pour forcer la diversification et diminuer ainsi le risque. Les techniques DCC GARCH sont plus efficaces dans la mesure où elles se soucient des changements dans les corrélations et qu'elles tiennent compte de leurs dynamiques dans le calcul des poids optimaux des portefeuilles. Les poids calculés lors de l'optimisation incorporent une plus grande quantité d'informations sur l'évolution des marchés. D'après nos résultats, le DCC GARCH apparaît comme la meilleure option que puisse avoir un gestionnaire qui veut améliorer ses rendements ou encore couvrir ses actifs contre les risques de marchés. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||