Estimation du temps de parcours aux soins de santé dans le district d'Ifanadiana.par Randriamihaja Mauricianot Ecole de management et d'innovation technologique - Master recherche en Informatique 2019 |

5.2. TraitementsLes traitements permettent d'explorer l'ensemble des données pour savoir des informations sur les donnéeset de l'analyserafin d'avoir des connaissances pour la création des modèles.Tous ces traitements sont effectués sur R, à part l'interpolation postérieur des prédictions des modèles qui était fait sur ArcGis. 5.2.1. Modélisation statistiqueIl permet d'établir les modèles statistiques appropriés en fonction de la distributiondes variables explicatives et réponse ainsi que leur relation, ce qu'on observe durant l'explorationdes différentes variables. Avec le développent des modèles, on a effectué deux étapes : 1) l'analyse exploratoires des données 2) la création des données statistiques. 5.2.2. Analyses exploratoiresCette étape consiste à l'analyse deseffets de chaque variable explicative par rapport au variable réponse. Les variables explicatives sont les suivantes :la pente, la distance, la pluie,l'occupation du sol et la vitesse comme la variable réponse. Pour chaque variable explicative, on a observéle lien par rapport à la variable réponse et de les catégoriser en fonction de l'analyse visuelle pour avoir les comparaisons possibles et d'interprétations fiables. Les sous-sectionssuivantesmontrent l'analyse exploratoirede chaque variable explicative : - La vitesse La vitesse est la variable à explique ou réponse. Il est important de connaitre la distribution de cette variable pour le choix du modèle (gaussien ou généralisé) etelle va être comparéeavec toutes les variables explicatives citées précédemment afin de voir les liaisons entre eux. - La pente La variable pente représente le niveau d'inclinaison du terrain par rapport aux reliefs, montagnes, ou collines. Pour le calcul, il existe deux méthodes, tels
que le calcul en dégrée et le calcul du pourcentage (%)
d'une pente. On a opté pour la dernière, celle du pourcentage
suivant la formule4(*) : Ensuite, les valeurs sont catégorisées pour avoir des valeurs qualitatives afin de comparer l'exploration des données obtenues. Ces explorations sont montrées dans la figure 7.2avec les deux valeurs (quantitative / qualitative). - La distance La variable distance est utilisée pour identifier
l'effet de la distance depuis le début du parcours sur la vitesse, sous
l'hypothèse que la vitesse réduit après une longue
marche.Elle est représentée sous forme de points en calculantla
distance des deux à l'aide d'une fonction nommée
« spDist », disponible sur R.On a utilisé la formule
suivante pour le calcul : Après le calcul, ces distances partielles sont regroupéesen une distance de parcourset catégoriséespour l'analyse d'exploration en qualitative.La valeur de la variable est catégorisée entre [0 ;13[ et [13 ; 22,9[, selon l'analyse de la figure 7.3. - La pluviométrie La variable pluie (précipitation)est une variable explicative qui représentel'influence de la pluiejournalière où le parcours a été effectuéspour tenir en compte ladétérioration du sol (boue,etc..).L'unité de mesure est en millimètres (mm). Durant l'exploration, on a utilisé la catégorisation des valeurs entre [0,10[, [10, 25] et]25,50]pour l'analyse qualitative par rapport à la mesurefaite par(Visser and Jones III 2010) et la valeur originale pour l'analyse quantitative. - Le pont Il est utilisé pour l'analyse exploratoire des véhicules uniquement. La variable explicative pontpermet de voir la vitesse des véhicules lorsqu'ils passent sur une passerelle. Elle est catégoriséeendeux valeurs telles que : oui et non. - La zone résidentielle Cette variableexplicative est utilisée pour la détection d'effet sur la vitesse ; lorsque les véhicules passentparune zone d'habitation. Il est catégorisé en deux valeurs telles que : oui et non. - La route On a utilisé la variable explicative route pour voir les relations entre les vitesses etles types des routes pour l'analyse exploratoires des véhicules.Il est catégorisé en quatre valeurs qui sont les suivantes : la route nationale, la route non goudronnées, la route non classifiée et le chemin. - L'individu Cette variable représente la variation de la vitesse pour chaque collecte de données durant les parcours effectués. Il permet de voir la différence des vitesses des individus. La valeur de la variable est catégorisée telles que l'ACC (la vitesse des accompagnements des agentscommunautaires), la vitesse de référence (la vitesse dans mes parcours à moi) et lesvillageois (la vitesse des villageoisqui ont participé à l'étude). - L'occupation du sol Pour la variable d'occupation du sol,on a utilisé différents types d'approchespour l'analyse des valeurs tels que : l'utilisation des valeurs quantitatifs en proportions (séparément par chaque type), l'utilisation des valeurs en catégorieentre ]0 ;0,1], [0,1 ;50[ et [50,100[pourcent, et l'utilisation du type de paysage majoritaire sur un parcours.Ces analysespermettent d'observer les effets d'occupation du solsur la vitesse des individus. * 4http://www.toujourspret.com/techniques/orientation/topographie/calcul_du_pourcentage_d%27une_pente.php |
|


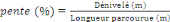
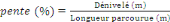 .
. 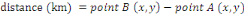
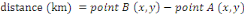 .
.